 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirror Descent Policy Optimization
Paper and Code
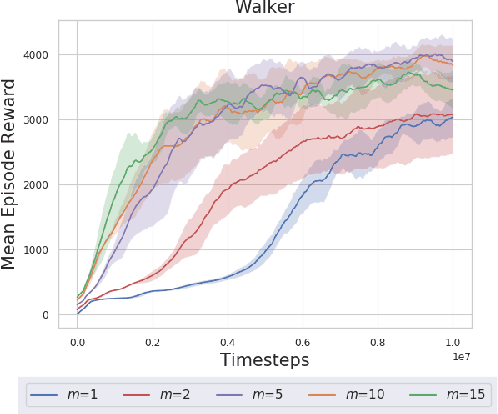

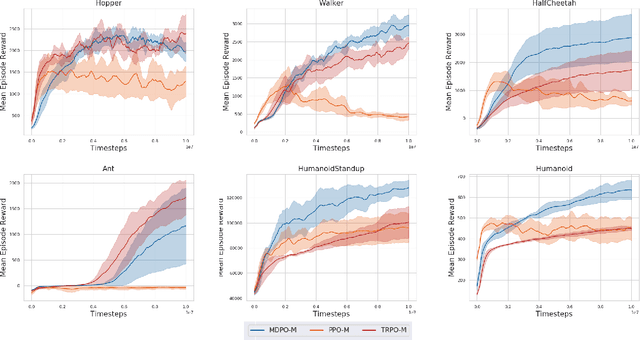
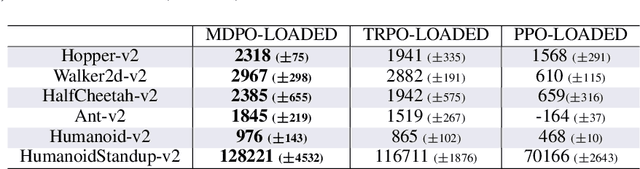
We propose deep Reinforcement Learning (RL) algorithms inspired by mirror descent, a well-known first-order trust region optimization method for solving constrained convex problems. Our approach, which we call as Mirror Descent Policy Optimization (MDPO), is based on the idea of iteratively solving a `trust-region' problem that minimizes a sum of two terms: a linearization of the objective function and a proximity term that restricts two consecutive updates to be close to each other. Following this approach we derive on-policy and off-policy variants of the MDPO algorithm and analyze their performance while emphasizing important implementation details, motivated by the existing theoretical framework. We highlight the connections between on-policy MDPO and two popular trust region RL algorithms: TRPO and PPO, and conduct a comprehensive empirical comparison of these algorithms. We then derive off-policy MDPO and compare its performance to existing approaches. Importantly, we show that the theoretical framework of MDPO can be scaled to deep RL while achieving good performance on popular benchmarks.