 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-filter compression for CNN inference acceleration
Paper and Code
May 18, 2020
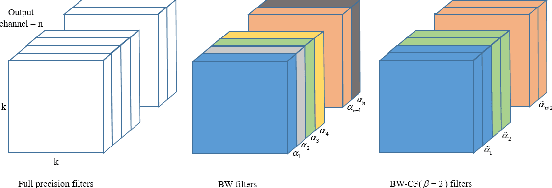
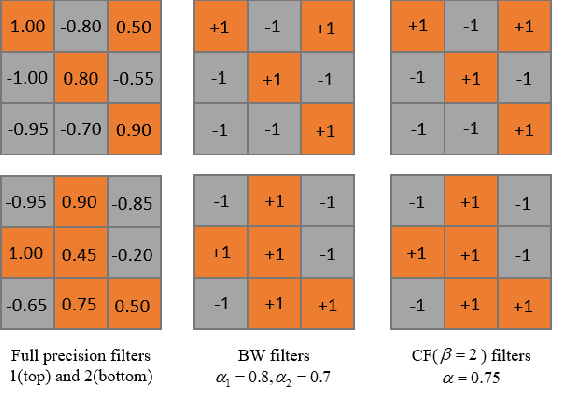
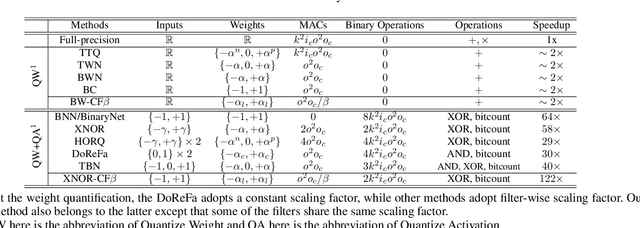
Convolution neural network demonstrates great capability for multiple tasks, such as image classification and many others. However, much resource is required to train a network. Hence much effort has been made to accelerate neural network by reducing precision of weights, activation, and gradient. However, these filter-wise quantification methods exist a natural upper limit, caused by the size of the kernel. Meanwhile, with the popularity of small kernel, the natural limit further decrease. To address this issue, we propose a new cross-filter compression method that can provide $\sim32\times$ memory savings and $122\times$ speed up in convolution operations. In our method, all convolution filters are quantized to given bits and spatially adjacent filters share the same scaling factor. Our compression method, based on Binary-Weight and XNOR-Net separately, is evaluated on CIFAR-10 and ImageNet dataset with widely used network structures, such as ResNet and VGG, and witness tolerable accuracy loss compared to state-of-the-art quantification methods.