 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Learning to Rank via Propensity Ratio Scoring
Paper and Code
May 18, 2020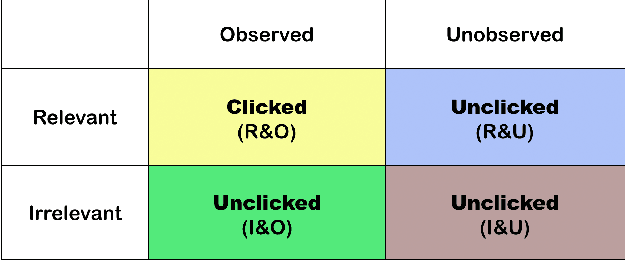
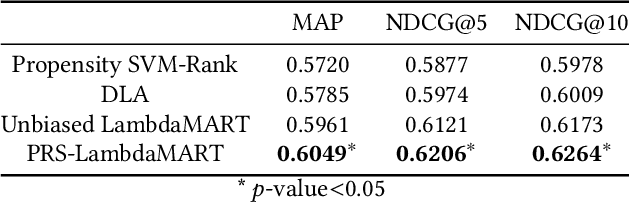
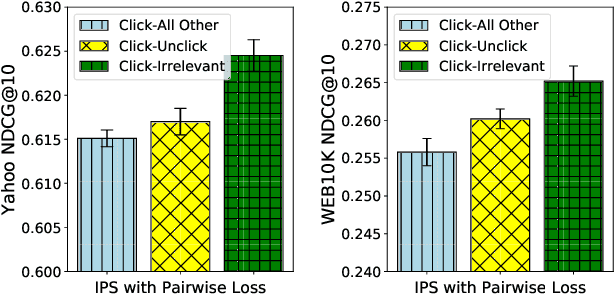
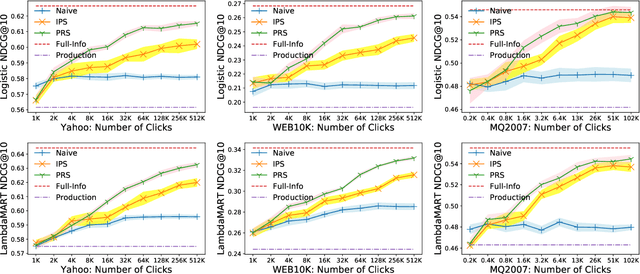
Implicit feedback, such as user clicks, is a major source of supervision for learning to rank (LTR) model estimation in modern retrieval systems. However, the inherent bias in such feedback greatly restricts the quality of the learnt ranker. Recent advances in unbiased LTR leverage Inverse Propensity Scoring (IPS) to tackle the bias issue. Though effective, it only corrects the bias introduced by treating clicked documents as relevant, but cannot handle the bias caused by treating unclicked ones as irrelevant. Because non-clicks do not necessarily stand for irrelevance (they might not be examined), IPS-based methods inevitably include loss from comparisons on relevant-relevant document pairs. This directly limits the effectiveness of ranking model learning. In this work, we first prove that in a LTR algorithm that is based on pairwise comparisons, only pairs with different labels (e.g., relevant-irrelevant pairs in binary case) should contribute to the loss function. The proof asserts sub-optimal results of the existing IPS-based methods in practice. We then derive a new weighting scheme called Propensity Ratio Scoring (PRS) that takes a holistic treatment on both clicks and non-clicks. Besides correcting the bias in clicked documents, PRS avoids relevant-relevant comparisons in LTR training in expectation and enjoys a lower variability. Our empirical study confirms that PRS ensures a more effective use of click data in various situations, which leads to its superior performance in an extensive set of LTR benchmarks.