 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Learning for Sparse Discrete Markov Random Fields with Controlled Gradient Approximation Error
Paper and Code
May 12, 2020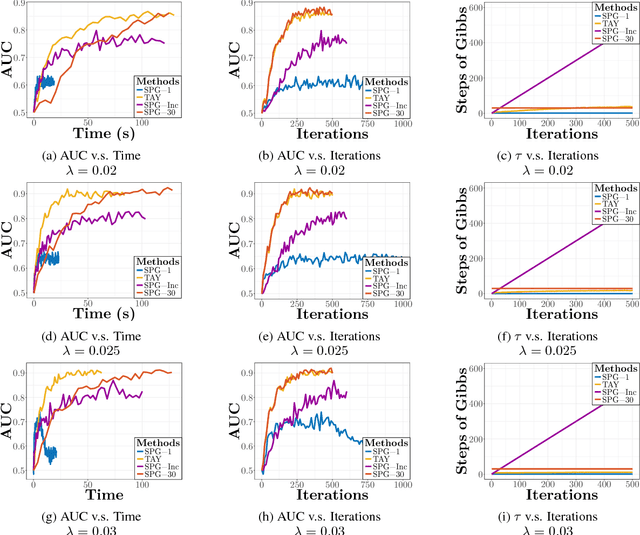
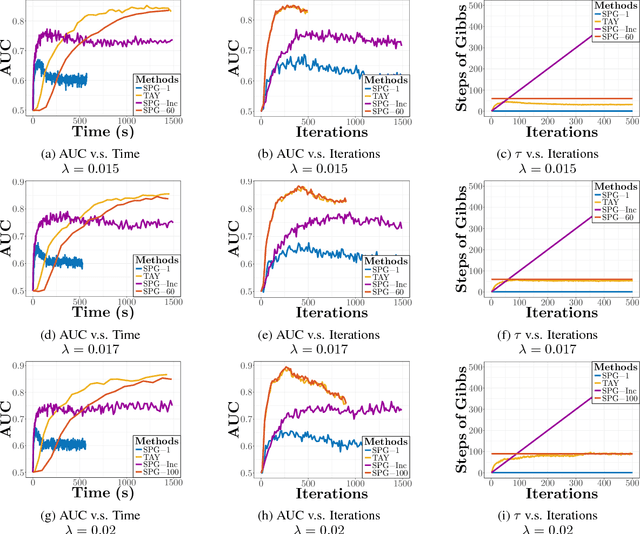
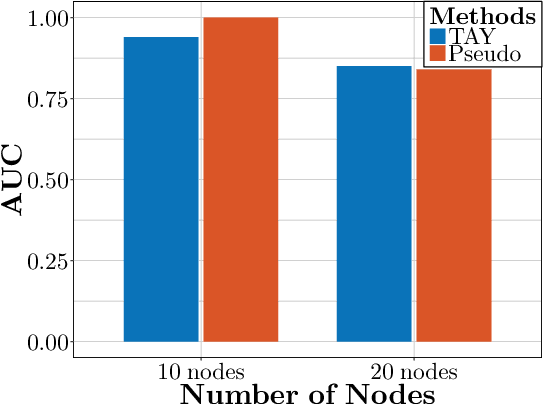
We study the $L_1$-regularized maximum likelihood estimator/estimation (MLE) problem for discrete Markov random fields (MRFs), where efficient and scalable learning requires both sparse regularization and approximate inference. To address these challenges, we consider a stochastic learning framework called stochastic proximal gradient (SPG; Honorio 2012a, Atchade et al. 2014,Miasojedow and Rejchel 2016). SPG is an inexact proximal gradient algorithm [Schmidtet al., 2011], whose inexactness stems from the stochastic oracle (Gibbs sampling) for gradient approximation - exact gradient evaluation is infeasible in general due to the NP-hard inference problem for discrete MRFs [Koller and Friedman, 2009]. Theoretically, we provide novel verifiable bounds to inspect and control the quality of gradient approximation. Empirically, we propose the tighten asymptotically (TAY) learning strategy based on the verifiable bounds to boost the performance of SPG.