 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Tests of Convolutional Neural Network and Graph Convolutional Network on HorovodRunner Enabled Spark Clusters
Paper and Code
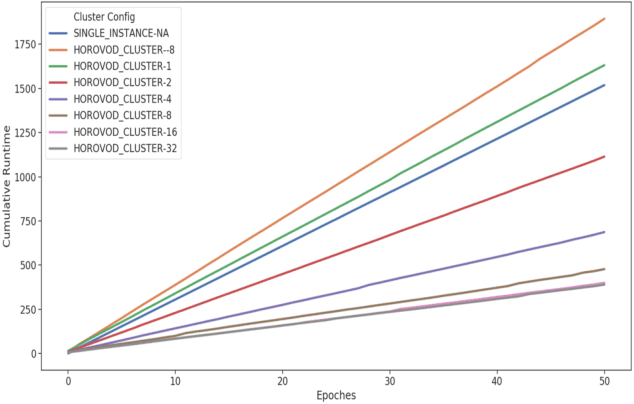
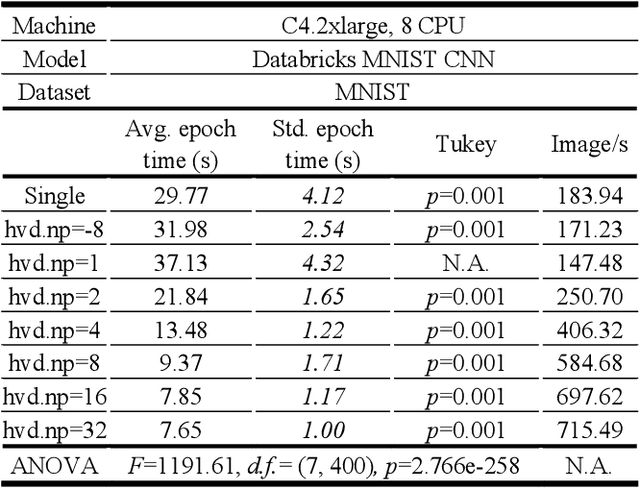
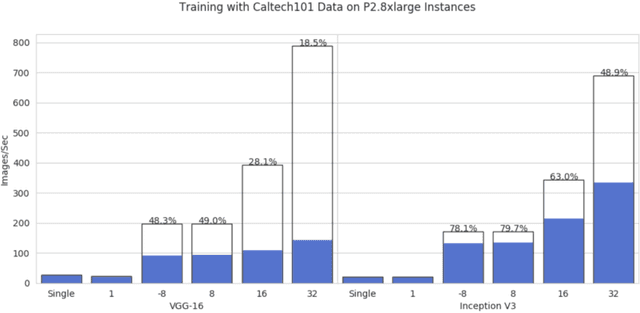
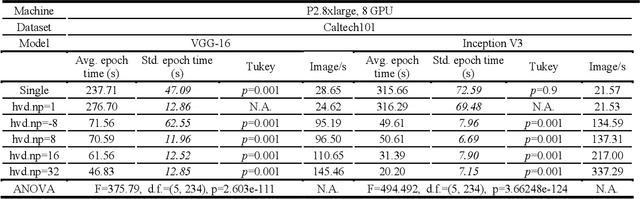
The freedom of fast iterations of distributed deep learning tasks is crucial for smaller companies to gain competitive advantages and market shares from big tech giants. HorovodRunner brings this process to relatively accessible spark clusters. There have been, however, no benchmark tests on HorovodRunner per se, nor specifically graph convolutional network (GCN, hereafter), and very limited scalability benchmark tests on Horovod, the predecessor requiring custom built GPU clusters. For the first time, we show that Databricks' HorovodRunner achieves significant lift in scaling efficiency for the convolutional neural network (CNN, hereafter) based tasks on both GPU and CPU clusters, but not the original GCN task. We also implemented the Rectified Adam optimizer for the first time in HorovodRunner.