 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Canonical Correlation Analysis for Sparse Count Data
Paper and Code
May 11, 2020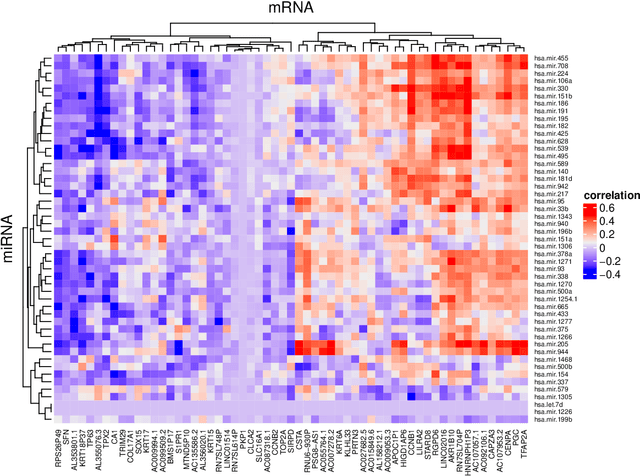
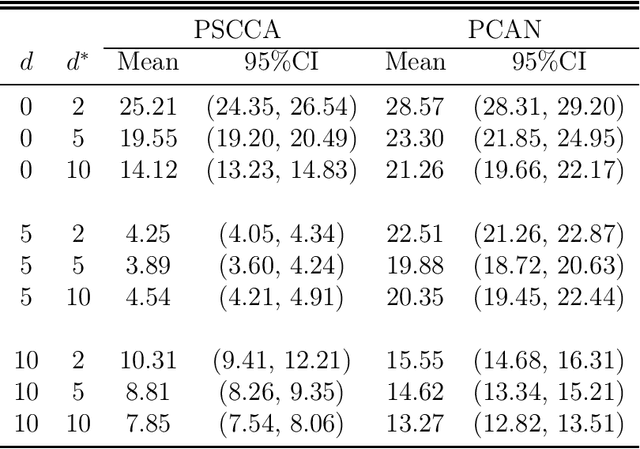
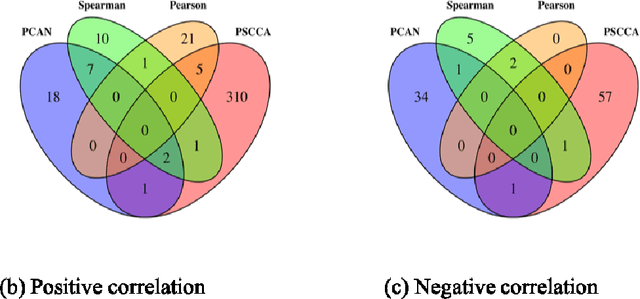
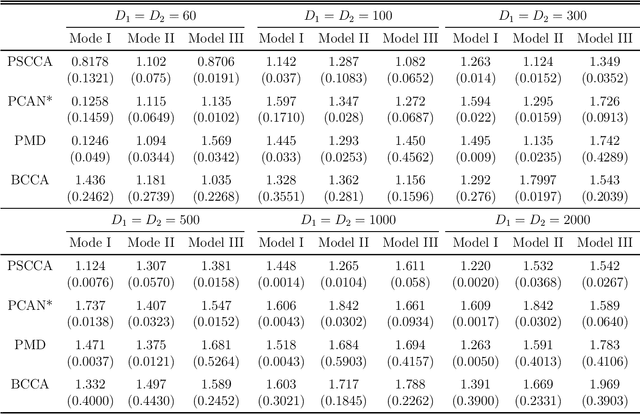
Canonical correlation analysis (CCA) is a classical and important multivariate technique for exploring the relationship between two sets of continuous variables. CCA has applications in many fields, such as genomics and neuroimaging. It can extract meaningful features as well as use these features for subsequent analysis. Although some sparse CCA methods have been developed to deal with high-dimensional problems, they are designed specifically for continuous data and do not consider the integer-valued data from next-generation sequencing platforms that exhibit very low counts for some important features. We propose a model-based probabilistic approach for correlation and canonical correlation estimation for two sparse count data sets (PSCCA). PSCCA demonstrates that correlations and canonical correlations estimated at the natural parameter level are more appropriate than traditional estimation methods applied to the raw data. We demonstrate through simulation studies that PSCCA outperforms other standard correlation approaches and sparse CCA approaches in estimating the true correlations and canonical correlations at the natural parameter level. We further apply the PSCCA method to study the association of miRNA and mRNA expression data sets from a squamous cell lung cancer study, finding that PSCCA can uncover a large number of strongly correlated pairs than standard correlation and other sparse CCA approaches.