 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Deep Learning Recommender Systems' Training On CPU Cluster Architectures
Paper and Code
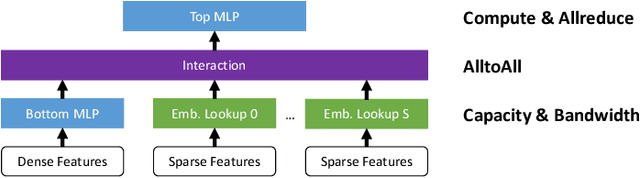
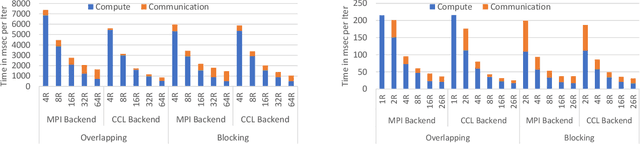
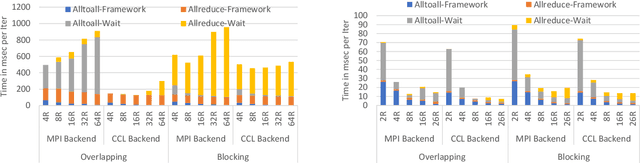

During the last two years, the goal of many researchers has been to squeeze the last bit of performance out of HPC system for AI tasks. Often this discussion is held in the context of how fast ResNet50 can be trained. Unfortunately, ResNet50 is no longer a representative workload in 2020. Thus, we focus on Recommender Systems which account for most of the AI cycles in cloud computing centers. More specifically, we focus on Facebook's DLRM benchmark. By enabling it to run on latest CPU hardware and software tailored for HPC, we are able to achieve more than two-orders of magnitude improvement in performance (110x) on a single socket compared to the reference CPU implementation, and high scaling efficiency up to 64 sockets, while fitting ultra-large datasets. This paper discusses the optimization techniques for the various operators in DLRM and which component of the systems are stressed by these different operators. The presented techniques are applicable to a broader set of DL workloads that pose the same scaling challenges/characteristics as DLRM.