 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat comprises a good talking-head video generation?: A Survey and Benchmark
Paper and Code
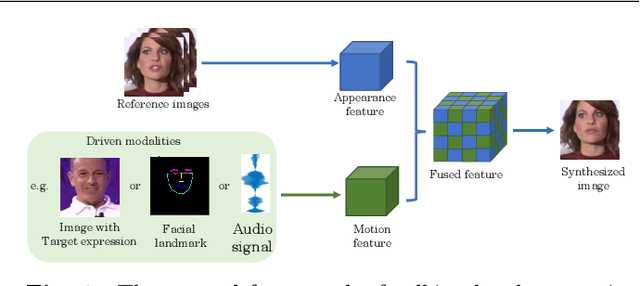
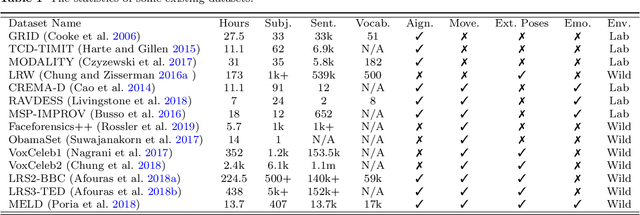
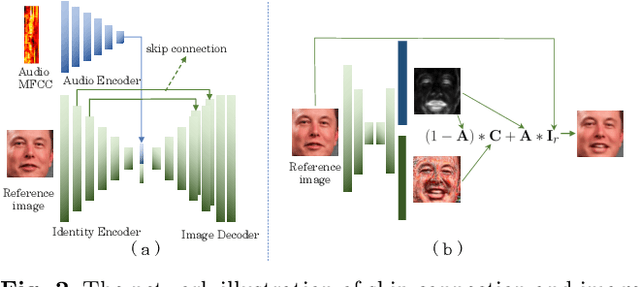

Over the years, performance evaluation has become essential in computer vision, enabling tangible progress in many sub-fields. While talking-head video generation has become an emerging research topic, existing evaluations on this topic present many limitations. For example, most approaches use human subjects (e.g., via Amazon MTurk) to evaluate their research claims directly. This subjective evaluation is cumbersome, unreproducible, and may impend the evolution of new research. In this work, we present a carefully-designed benchmark for evaluating talking-head video generation with standardized dataset pre-processing strategies. As for evaluation, we either propose new metrics or select the most appropriate ones to evaluate results in what we consider as desired properties for a good talking-head video, namely, identity preserving, lip synchronization, high video quality, and natural-spontaneous motion. By conducting a thoughtful analysis across several state-of-the-art talking-head generation approaches, we aim to uncover the merits and drawbacks of current methods and point out promising directions for future work. All the evaluation code is available at: https://github.com/lelechen63/talking-head-generation-survey.