 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating SOAP Notes from Doctor-Patient Conversations
Paper and Code
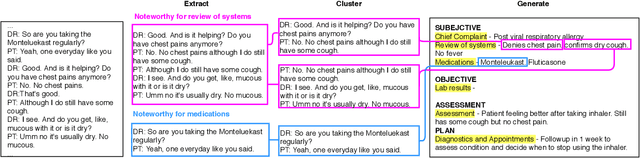
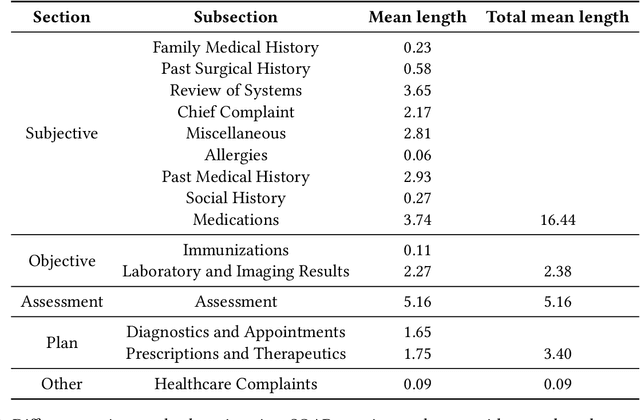
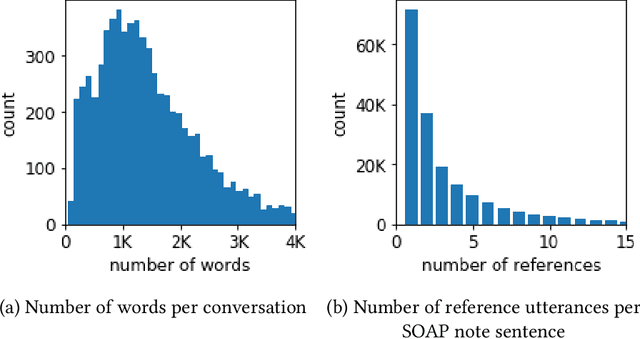
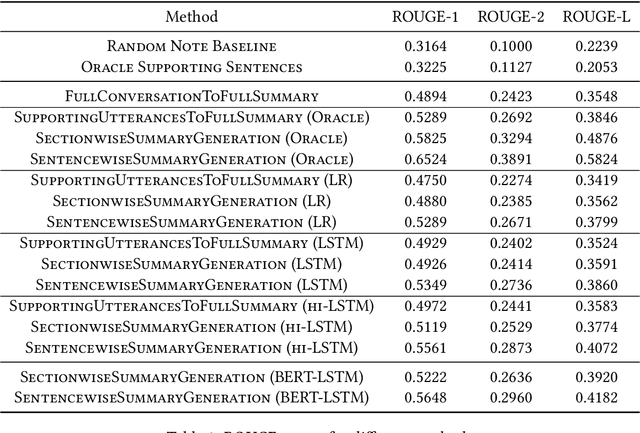
Following each patient visit, physicians must draft detailed clinical summaries called SOAP notes. Moreover, with electronic health records, these notes must be digitized. For all the benefits of this documentation the process remains onerous, contributing to increasing physician burnout. In a parallel development, patients increasingly record audio from their visits (with consent), often through dedicated apps. In this paper, we present the first study to evaluate complete pipelines for leveraging these transcripts to train machine learning model to generate these notes. We first describe a unique dataset of patient visit records, consisting of transcripts, paired SOAP notes, and annotations marking noteworthy utterances that support each summary sentence. We decompose the problem into extractive and abstractive subtasks, exploring a spectrum of approaches according to how much they demand from each component. Our best performing method first (i) extracts noteworthy utterances via multi-label classification assigns them to summary section(s); (ii) clusters noteworthy utterances on a per-section basis; and (iii) generates the summary sentences by conditioning on the corresponding cluster and the subsection of the SOAP sentence to be generated. Compared to an end-to-end approach that generates the full SOAP note from the full conversation, our approach improves by 7 ROUGE-1 points. Oracle experiments indicate that fixing our generative capabilities, improvements in extraction alone could provide (up to) a further 9 ROUGE point gain.