 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Guided Aspect Classification for Domain-Specific Texts
Paper and Code
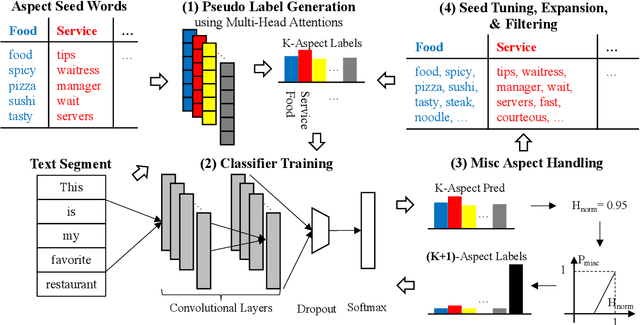
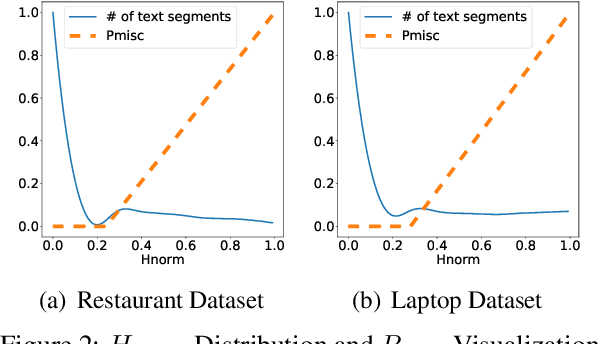
Aspect classification, identifying aspects of text segments, facilitates numerous applications, such as sentiment analysis and review summarization. To alleviate the human effort on annotating massive texts, in this paper, we study the problem of classifying aspects based on only a few user-provided seed words for pre-defined aspects. The major challenge lies in how to handle the noisy misc aspect, which is designed for texts without any pre-defined aspects. Even domain experts have difficulties to nominate seed words for the misc aspect, making existing seed-driven text classification methods not applicable. We propose a novel framework, ARYA, which enables mutual enhancements between pre-defined aspects and the misc aspect via iterative classifier training and seed updating. Specifically, it trains a classifier for pre-defined aspects and then leverages it to induce the supervision for the misc aspect. The prediction results of the misc aspect are later utilized to filter out noisy seed words for pre-defined aspects. Experiments in two domains demonstrate the superior performance of our proposed framework, as well as the necessity and importance of properly modeling the misc aspect.