 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Recommender Systems Challenge on Twitter's Home Timeline
Paper and Code
Apr 28, 2020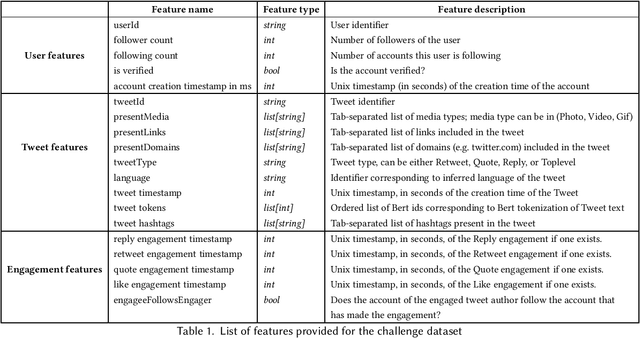
Recommender systems constitute the core engine of most social network platforms nowadays, aiming to maximize user satisfaction along with other key business objectives. Twitter is no exception. Despite the fact that Twitter data has been extensively used to understand socioeconomic and political phenomena and user behaviour, the implicit feedback provided by users on Tweets through their engagements on the Home Timeline has only been explored to a limited extent. At the same time, there is a lack of large-scale public social network datasets that would enable the scientific community to both benchmark and build more powerful and comprehensive models that tailor content to user interests. By releasing an original dataset of 160 million Tweets along with engagement information, Twitter aims to address exactly that. During this release, special attention is drawn on maintaining compliance with existing privacy laws. Apart from user privacy, this paper touches on the key challenges faced by researchers and professionals striving to predict user engagements. It further describes the key aspects of the RecSys 2020 Challenge that was organized by ACM RecSys in partnership with Twitter using this dataset.