 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond 512 Tokens: Siamese Multi-depth Transformer-based Hierarchical Encoder for Document Matching
Paper and Code

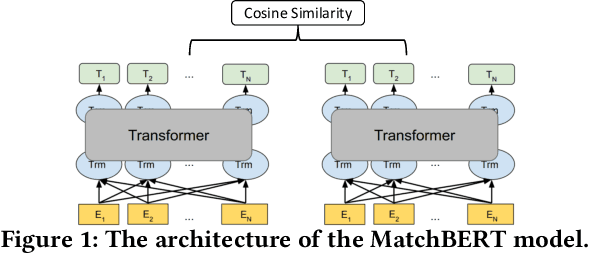
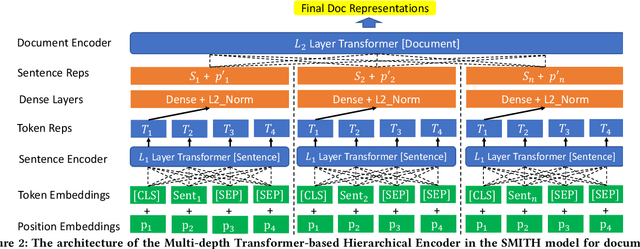
Many information retrieval and natural language processing problems can be formalized as a semantic matching task. However, the existing work in this area has been focused in large part on the matching between short texts like finding answer spans, sentences and passages given a query or a natural language question. Semantic matching between long-form texts like documents, which can be applied to applications such as document clustering, news recommendation and related article recommendation, is relatively less explored and needs more research effort. In recent years, self-attention based models like Transformers and BERT have achieved state-of-the-art performance in several natural language understanding tasks. These kinds of models, however, are still restricted to short text sequences like sentences due to the quadratic computational time and space complexity of self-attention with respect to the input sequence length. In this paper, we address these issues by proposing the Siamese Multi-depth Transformer-based Hierarchical (SMITH) Encoder for document representation learning and matching, which contains several novel design choices to adapt self-attention models for long text inputs. For model pre-training, we propose the masked sentence block language modeling task in addition to the original masked word language modeling task used in BERT, to capture sentence block relations within a document. The experimental results on several benchmark data sets for long-form document matching show that our proposed SMITH model outperforms the previous state-of-the-art Siamese matching models including hierarchical attention, multi-depth attention-based hierarchical recurrent neural network, and BERT for long-form document matching, and increases the maximum input text length from 512 to 2048 when compared with BERT-based baseline methods.