 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Trojan Attacks on Deep Neural Networks
Paper and Code
May 27, 2020
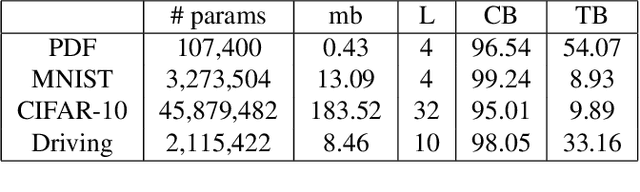
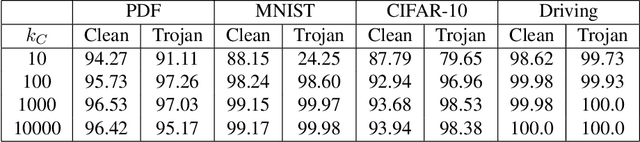
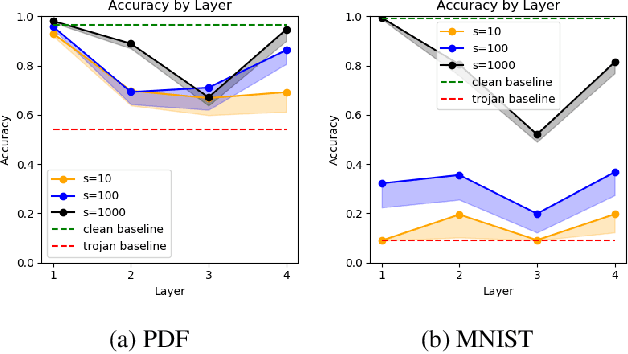
Like all software systems, the execution of deep learning models is dictated in part by logic represented as data in memory. For decades, attackers have exploited traditional software programs by manipulating this data. We propose a live attack on deep learning systems that patches model parameters in memory to achieve predefined malicious behavior on a certain set of inputs. By minimizing the size and number of these patches, the attacker can reduce the amount of network communication and memory overwrites, with minimal risk of system malfunctions or other detectable side effects. We demonstrate the feasibility of this attack by computing efficient patches on multiple deep learning models. We show that the desired trojan behavior can be induced with a few small patches and with limited access to training data. We describe the details of how this attack is carried out on real systems and provide sample code for patching TensorFlow model parameters in Windows and in Linux. Lastly, we present a technique for effectively manipulating entropy on perturbed inputs to bypass STRIP, a state-of-the-art run-time trojan detection technique.