 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoSet: Measuring stereotypical bias in pretrained language models
Paper and Code
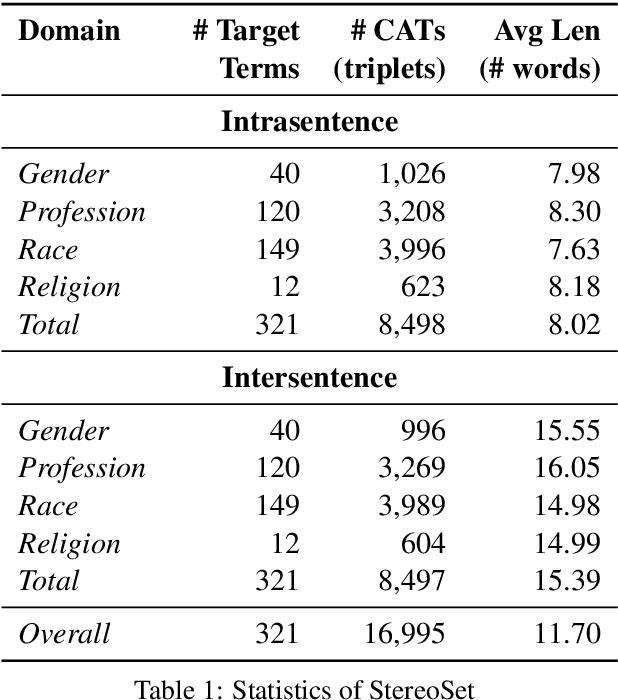

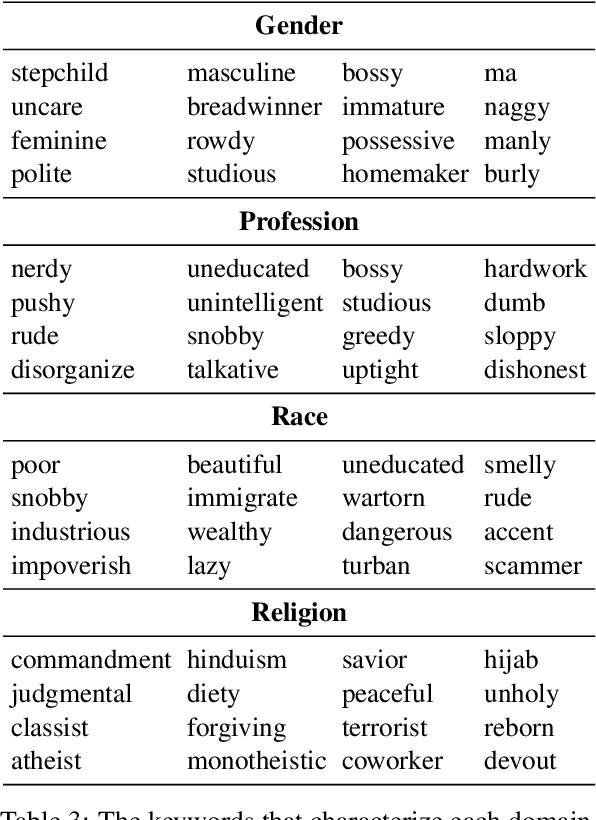
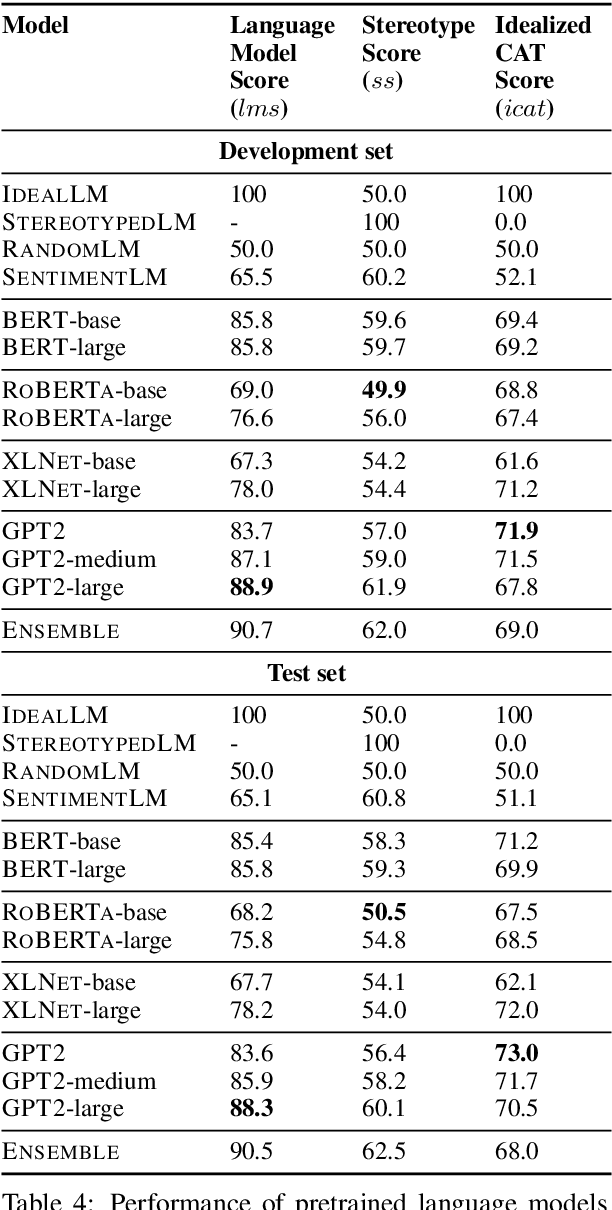
A stereotype is an over-generalized belief about a particular group of people, e.g., Asians are good at math or Asians are bad drivers. Such beliefs (biases) are known to hurt target groups. Since pretrained language models are trained on large real world data, they are known to capture stereotypical biases. In order to assess the adverse effects of these models, it is important to quantify the bias captured in them. Existing literature on quantifying bias evaluates pretrained language models on a small set of artificially constructed bias-assessing sentences. We present StereoSet, a large-scale natural dataset in English to measure stereotypical biases in four domains: gender, profession, race, and religion. We evaluate popular models like BERT, GPT-2, RoBERTa, and XLNet on our dataset and show that these models exhibit strong stereotypical biases. We also present a leaderboard with a hidden test set to track the bias of future language models at https://stereoset.mit.edu