 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Tumor Tissue Region Detection with Accelerated Deep Convolutional Neural Networks
Paper and Code
Apr 18, 2020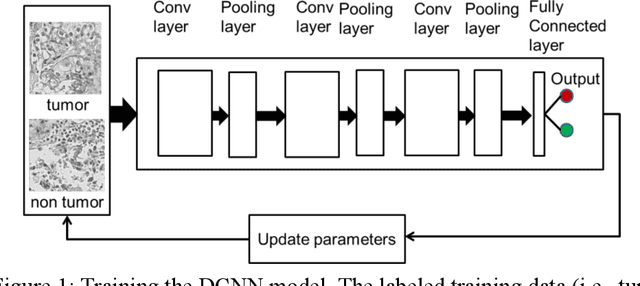
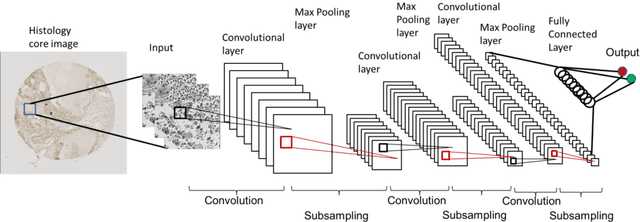

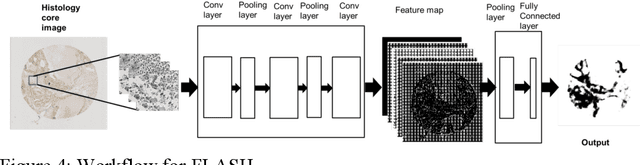
Manual annotation of pathology slides for cancer diagnosis is laborious and repetitive. Therefore, much effort has been devoted to develop computer vision solutions. Our approach, (FLASH), is based on a Deep Convolutional Neural Network (DCNN) architecture. It reduces computational costs and is faster than typical deep learning approaches by two orders of magnitude, making high throughput processing a possibility. In computer vision approaches using deep learning methods, the input image is subdivided into patches which are separately passed through the neural network. Features extracted from these patches are used by the classifier to annotate the corresponding region. Our approach aggregates all the extracted features into a single matrix before passing them to the classifier. Previously, the features are extracted from overlapping patches. Aggregating the features eliminates the need for processing overlapping patches, which reduces the computations required. DCCN and FLASH demonstrate high sensitivity (~ 0.96), good precision (~0.78) and high F1 scores (~0.84). The average time taken to process each sample for FLASH and DCNN is 96.6 seconds and 9489.20 seconds, respectively. Our approach was approximately 100 times faster than the original DCNN approach while simultaneously preserving high accuracy and precision.