 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo sequence-to-sequence VAEs learn global features of sentences?
Paper and Code
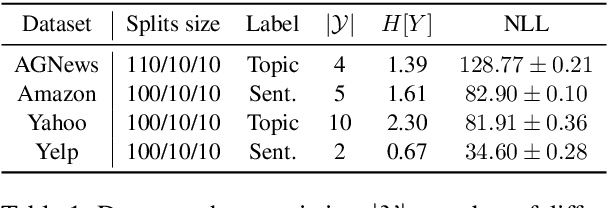
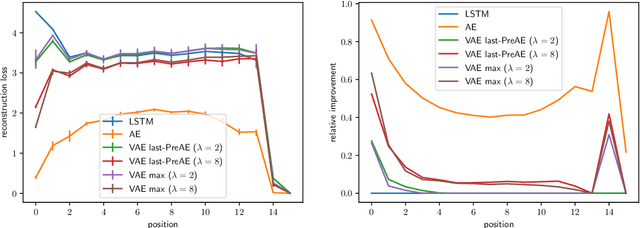
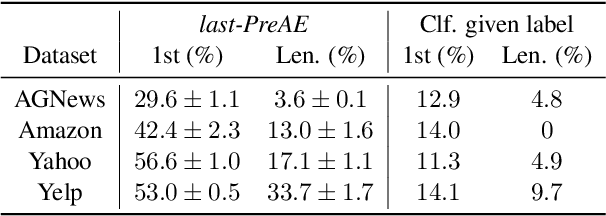
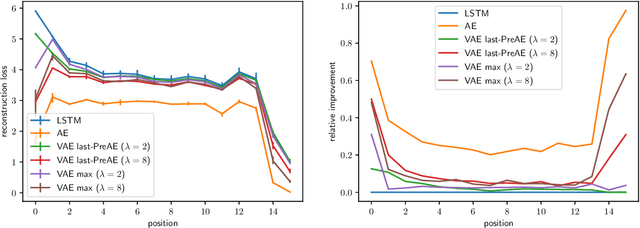
A longstanding goal in NLP is to compute global sentence representations. Such representations would be useful for sample-efficient semi-supervised learning and controllable text generation. To learn to represent global and local information separately, Bowman & al. (2016) proposed to train a sequence-to-sequence model with the variational auto-encoder (VAE) objective. What precisely is encoded in these latent variables expected to capture global features? We measure which words benefit most from the latent information by decomposing the reconstruction loss per position in the sentence. Using this method, we see that VAEs are prone to memorizing the first words and the sentence length, drastically limiting their usefulness. To alleviate this, we propose variants based on bag-of-words assumptions and language model pretraining. These variants learn latents that are more global: they are more predictive of topic or sentiment labels, and their reconstructions are more faithful to the labels of the original documents.