 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Single-View 3-D Object Reconstruction with Compositional Priors
Paper and Code
May 03, 2020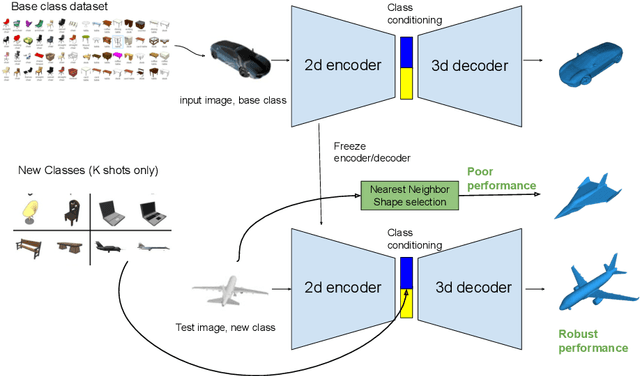
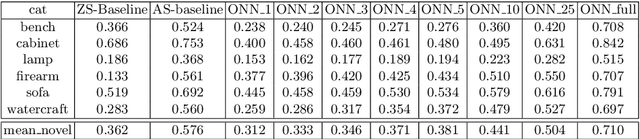
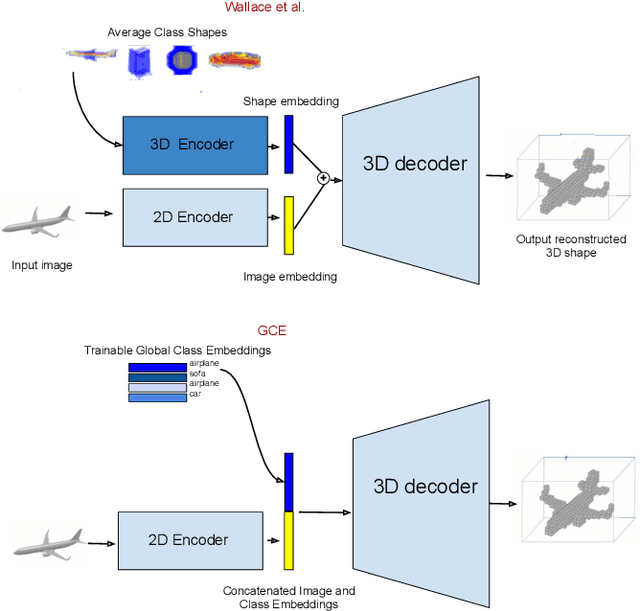
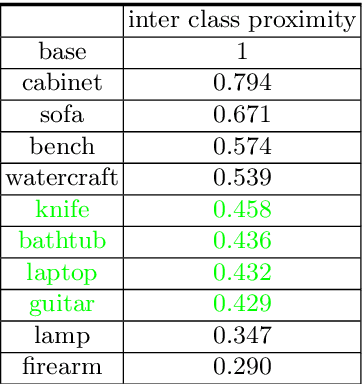
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. However, recent work has challenged this belief, showing that complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per category data in standard benchmarks. On the other hand settings where 3D shape must be inferred for new categories with few examples are more natural and require models that generalize about shapes. In this work we demonstrate experimentally that naive baselines do not apply when the goal is to learn to reconstruct novel objects using very few examples, and that in a \emph{few-shot} learning setting, the network must learn concepts that can be applied to new categories, avoiding rote memorization. To address deficiencies in existing approaches to this problem, we propose three approaches that efficiently integrate a class prior into a 3D reconstruction model, allowing to account for intra-class variability and imposing an implicit compositional structure that the model should learn. Experiments on the popular ShapeNet database demonstrate that our method significantly outperform existing baselines on this task in the few-shot setting.