 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning for Fashion Style Based on Hierarchical Multimodal Representation
Paper and Code

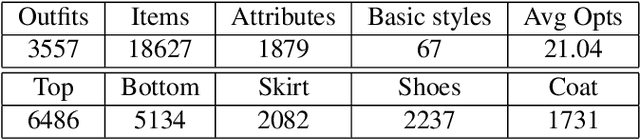
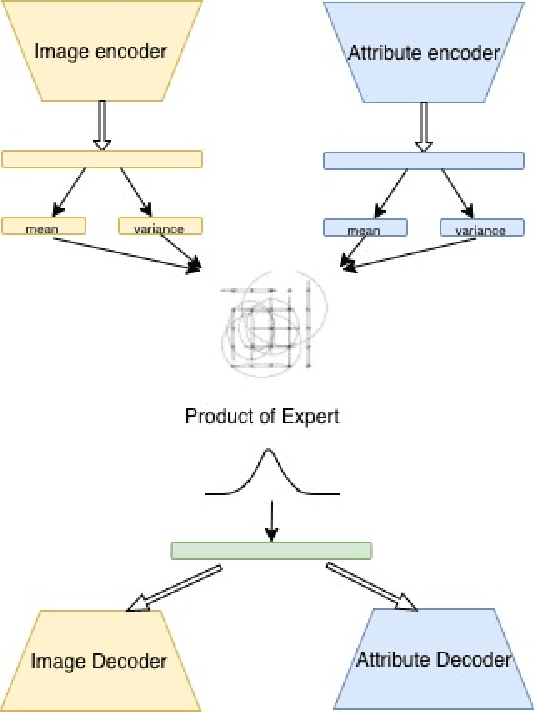
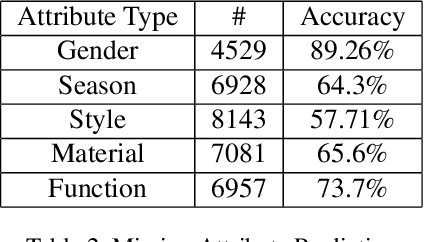
Fashion is a complex social phenomenon. People follow fashion styles from demonstrations by experts or fashion icons. However, for machine agent, learning to imitate fashion experts from demonstrations can be challenging, especially for complex styles in environments with high-dimensional, multimodal observations. Most existing research regarding fashion outfit composition utilizes supervised learning methods to mimic the behaviors of style icons. These methods suffer from distribution shift: because the agent greedily imitates some given outfit demonstrations, it can drift away from one style to another styles given subtle differences. In this work, we propose an adversarial inverse reinforcement learning formulation to recover reward functions based on hierarchical multimodal representation (HM-AIRL) during the imitation process. The hierarchical joint representation can more comprehensively model the expert composited outfit demonstrations to recover the reward function. We demonstrate that the proposed HM-AIRL model is able to recover reward functions that are robust to changes in multimodal observations, enabling us to learn policies under significant variation between different styles.