 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Neural Tangent Kernel of Deep Networks with Orthogonal Initialization
Paper and Code

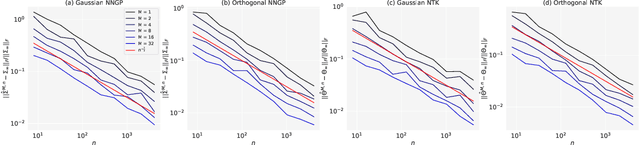
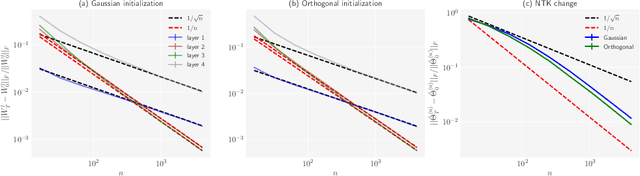
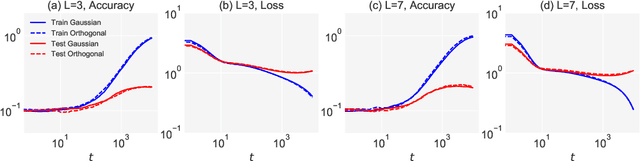
In recent years, a critical initialization scheme of orthogonal initialization on deep nonlinear networks has been proposed. The orthogonal weights are crucial to achieve {\it dynamical isometry} for random networks, where the entire spectrum of singular values of an input-output Jacobian are around one. The strong empirical evidence that orthogonal initialization in linear networks and the linear regime of nonlinear networks can speed up training than Gaussian initialization raise great interests. One recent work has proven the benefit of orthogonal initialization in linear networks. However, the dynamics behind it have not been revealed on nonlinear networks. In this work, we study the Neural Tangent Kernel (NTK), which can describe dynamics of gradient descent training of wide network, and focus on fully-connected and nonlinear networks with orthogonal initialization. We prove that NTK of Gaussian and orthogonal weights are equal when the network width is infinite, resulting in a conclusion that orthogonal initialization can speed up training is a finite-width effect in the small learning rate regime. Then we find that during training, the NTK of infinite-width network with orthogonal initialization stays constant theoretically and varies at a rate of the same order as Gaussian ones empirically, as the width tends to infinity. Finally, we conduct a thorough empirical investigation of training speed on CIFAR10 datasets and show the benefit of orthogonal initialization lies in the large learning rate and depth phase in a linear regime of nonlinear network.