 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairALM: Augmented Lagrangian Method for Training Fair Models with Little Regret
Paper and Code
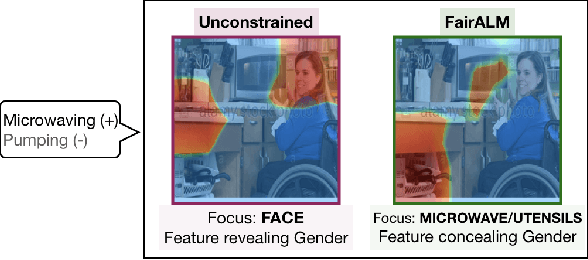
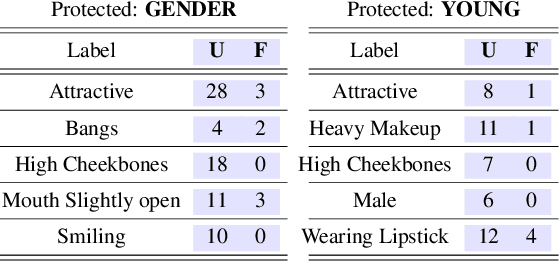
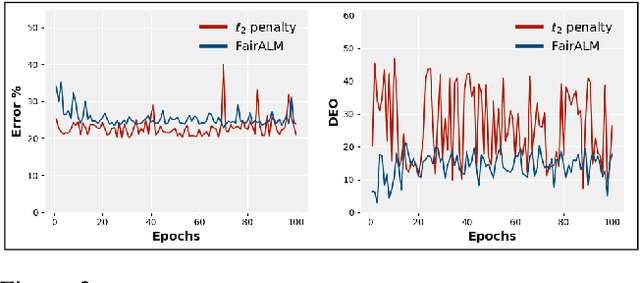
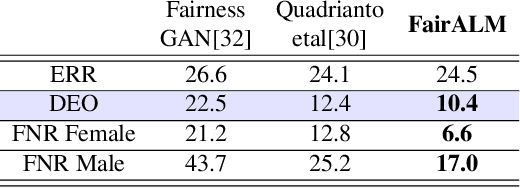
Algorithmic decision making based on computer vision and machine learning technologies continue to permeate our lives. But issues related to biases of these models and the extent to which they treat certain segments of the population unfairly, have led to concern in the general public. It is now accepted that because of biases in the datasets we present to the models, a fairness-oblivious training will lead to unfair models. An interesting topic is the study of mechanisms via which the de novo design or training of the model can be informed by fairness measures. Here, we study mechanisms that impose fairness concurrently while training the model. While existing fairness based approaches in vision have largely relied on training adversarial modules together with the primary classification/regression task, in an effort to remove the influence of the protected attribute or variable, we show how ideas based on well-known optimization concepts can provide a simpler alternative. In our proposed scheme, imposing fairness just requires specifying the protected attribute and utilizing our optimization routine. We provide a detailed technical analysis and present experiments demonstrating that various fairness measures from the literature can be reliably imposed on a number of training tasks in vision in a manner that is interpretable.