 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook-into-Object: Self-supervised Structure Modeling for Object Recognition
Paper and Code
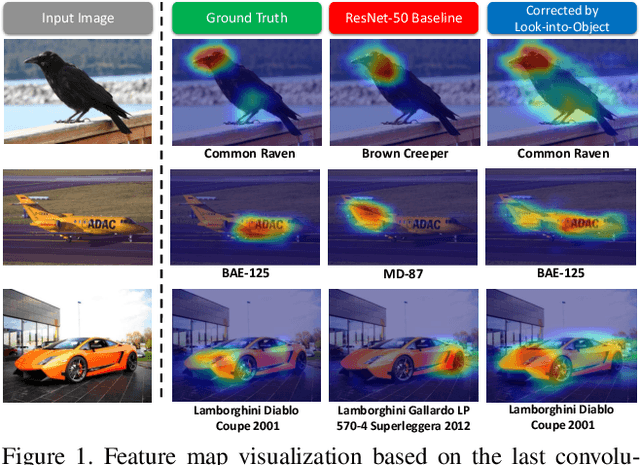
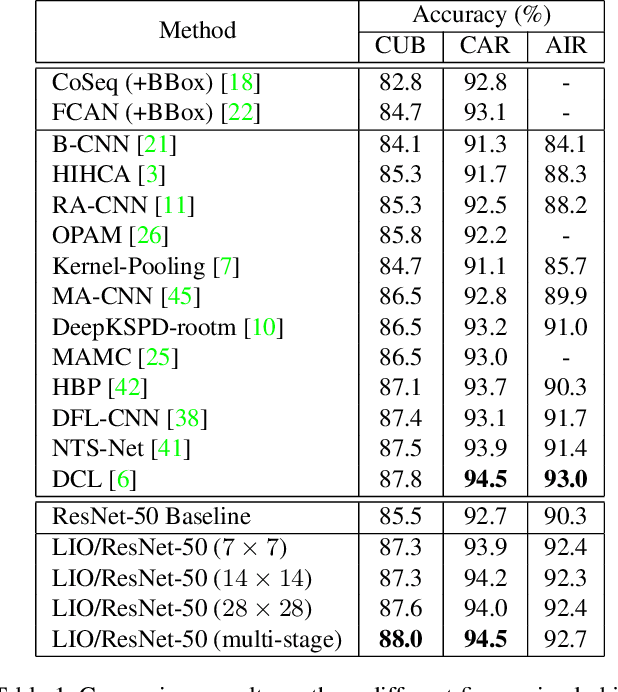
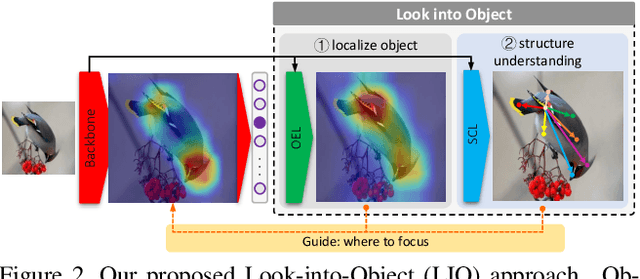

Most object recognition approaches predominantly focus on learning discriminative visual patterns while overlooking the holistic object structure. Though important, structure modeling usually requires significant manual annotations and therefore is labor-intensive. In this paper, we propose to "look into object" (explicitly yet intrinsically model the object structure) through incorporating self-supervisions into the traditional framework. We show the recognition backbone can be substantially enhanced for more robust representation learning, without any cost of extra annotation and inference speed. Specifically, we first propose an object-extent learning module for localizing the object according to the visual patterns shared among the instances in the same category. We then design a spatial context learning module for modeling the internal structures of the object, through predicting the relative positions within the extent. These two modules can be easily plugged into any backbone networks during training and detached at inference time. Extensive experiments show that our look-into-object approach (LIO) achieves large performance gain on a number of benchmarks, including generic object recognition (ImageNet) and fine-grained object recognition tasks (CUB, Cars, Aircraft). We also show that this learning paradigm is highly generalizable to other tasks such as object detection and segmentation (MS COCO). Project page: https://github.com/JDAI-CV/LIO.