 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCMD: Distance-based Classification Using Mixture Distributions on Microbiome Data
Paper and Code
Mar 29, 2020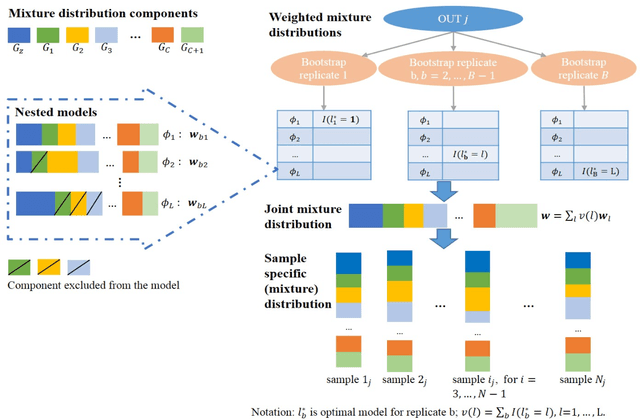

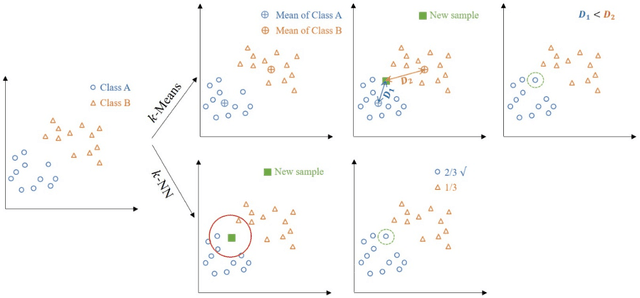
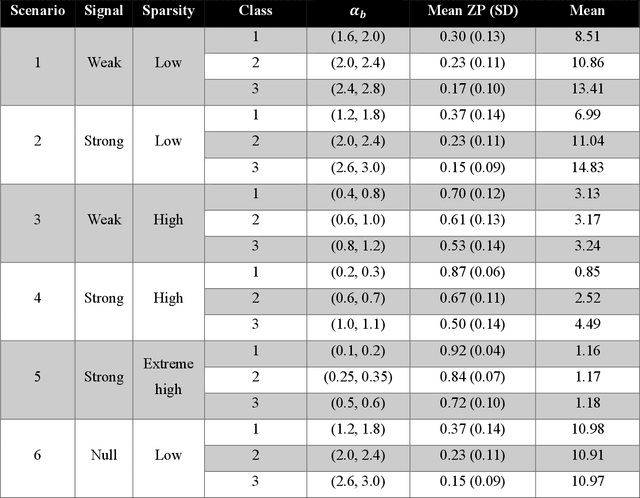
Current advances in next generation sequencing techniques have allowed researchers to conduct comprehensive research on microbiome and human diseases, with recent studies identifying associations between human microbiome and health outcomes for a number of chronic conditions. However, microbiome data structure, characterized by sparsity and skewness, presents challenges to building effective classifiers. To address this, we present an innovative approach for distance-based classification using mixture distributions (DCMD). The method aims to improve classification performance when using microbiome community data, where the predictors are composed of sparse and heterogeneous count data. This approach models the inherent uncertainty in sparse counts by estimating a mixture distribution for the sample data, and representing each observation as a distribution, conditional on observed counts and the estimated mixture, which are then used as inputs for distance-based classification. The method is implemented into a k-means and k-nearest neighbours framework and we identify two distance metrics that produce optimal results. The performance of the model is assessed using simulations and applied to a human microbiome study, with results compared against a number of existing machine learning and distance-based approaches. The proposed method is competitive when compared to the machine learning approaches and showed a clear improvement over commonly used distance-based classifiers. The range of applicability and robustness make the proposed method a viable alternative for classification using sparse microbiome count data.