 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipelined Backpropagation at Scale: Training Large Models without Batches
Paper and Code
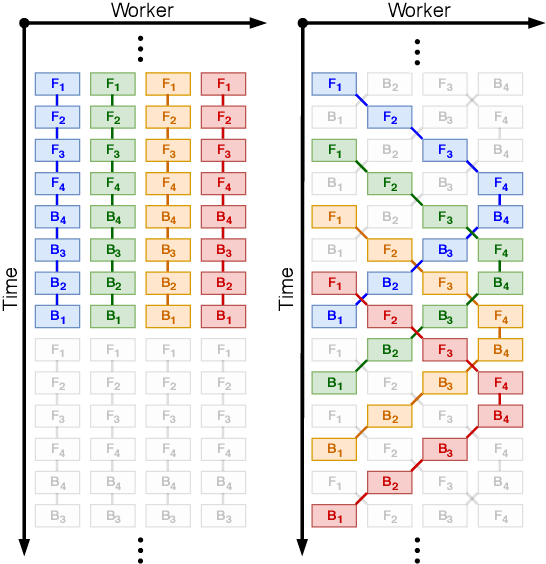
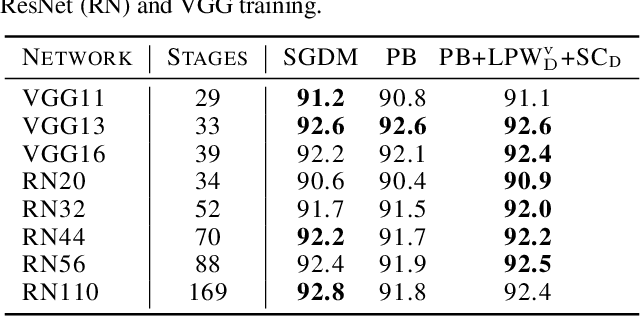
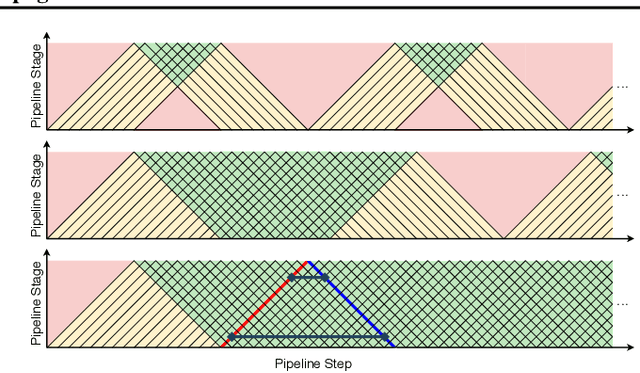
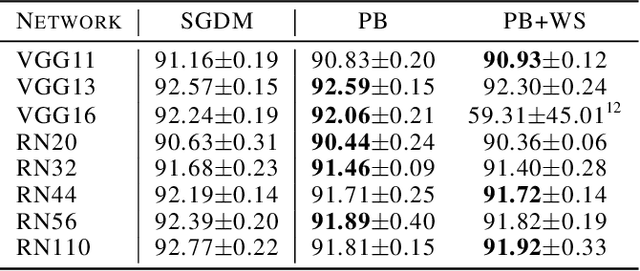
Parallelism is crucial for accelerating the training of deep neural networks. Pipeline parallelism can provide an efficient alternative to traditional data parallelism by allowing workers to specialize. Performing mini-batch SGD using pipeline parallelism has the overhead of filling and draining the pipeline. Pipelined Backpropagation updates the model parameters without draining the pipeline. This removes the overhead but introduces stale gradients and inconsistency between the weights used on the forward and backward passes, reducing final accuracy and the stability of training. We introduce Spike Compensation and Linear Weight Prediction to mitigate these effects. Analysis on a convex quadratic shows that both methods effectively counteract staleness. We train multiple convolutional networks at a batch size of one, completely replacing batch parallelism with fine-grained pipeline parallelism. With our methods, Pipelined Backpropagation achieves full accuracy on CIFAR-10 and ImageNet without hyperparameter tuning.