 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-aware Bayesian Optimization
Paper and Code
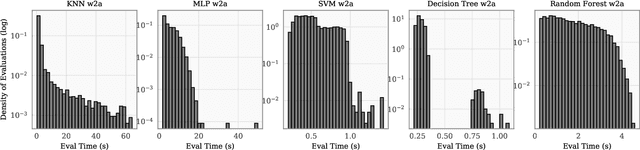
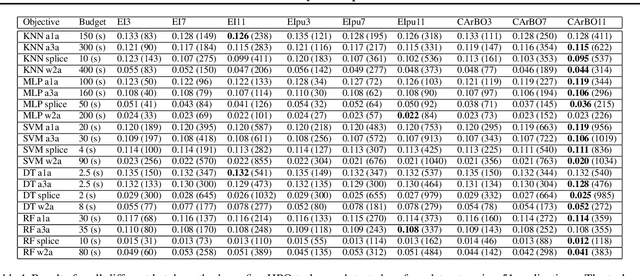
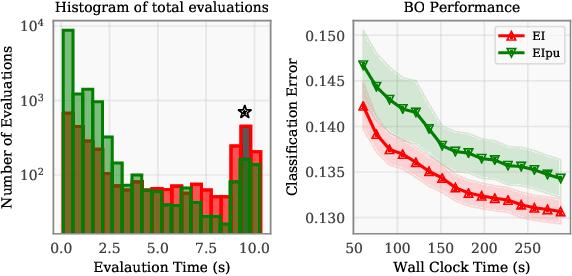
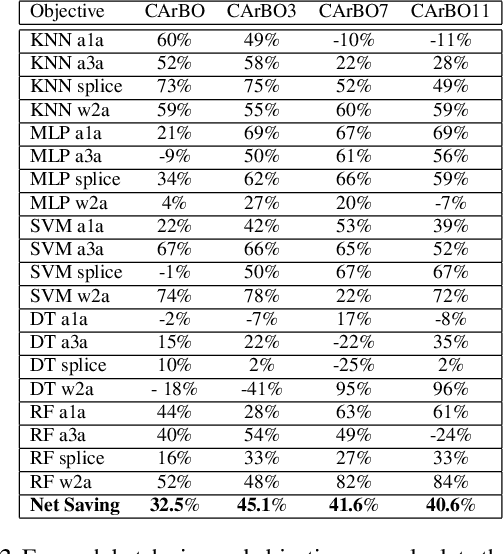
Bayesian optimization (BO) is a class of global optimization algorithms, suitable for minimizing an expensive objective function in as few function evaluations as possible. While BO budgets are typically given in iterations, this implicitly measures convergence in terms of iteration count and assumes each evaluation has identical cost. In practice, evaluation costs may vary in different regions of the search space. For example, the cost of neural network training increases quadratically with layer size, which is a typical hyperparameter. Cost-aware BO measures convergence with alternative cost metrics such as time, energy, or money, for which vanilla BO methods are unsuited. We introduce Cost Apportioned BO (CArBO), which attempts to minimize an objective function in as little cost as possible. CArBO combines a cost-effective initial design with a cost-cooled optimization phase which depreciates a learned cost model as iterations proceed. On a set of 20 black-box function optimization problems we show that, given the same cost budget, CArBO finds significantly better hyperparameter configurations than competing methods.