 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Privacy Risks of Machine Learning Models
Paper and Code
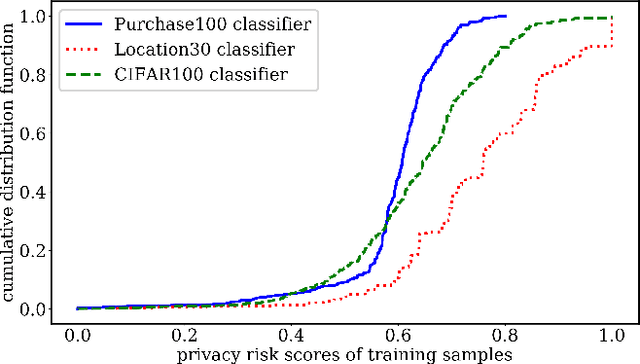
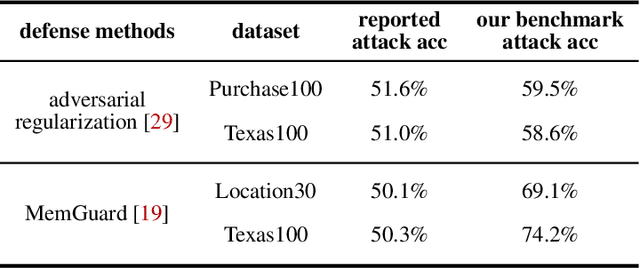
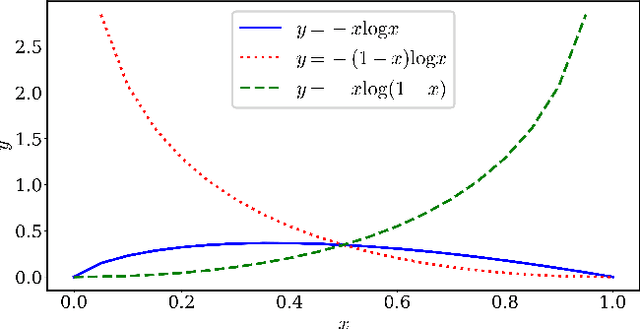
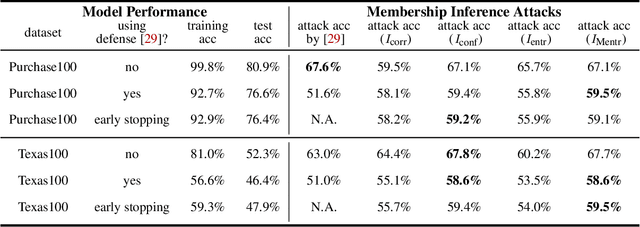
Machine learning models are prone to memorizing sensitive data, making them vulnerable to membership inference attacks in which an adversary aims to guess if an input sample was used to train the model. In this paper, we show that prior work on membership inference attacks may severely underestimate the privacy risks by relying solely on training custom neural network classifiers to perform attacks and focusing only on the aggregate results over data samples, such as the attack accuracy. To overcome these limitations, we first propose to benchmark membership inference privacy risks by improving existing non-neural network based inference attacks and proposing a new inference attack method based on a modification of prediction entropy. We also propose benchmarks for defense mechanisms by accounting for adaptive adversaries with knowledge of the defense and also accounting for the trade-off between model accuracy and privacy risks. Using our benchmark attacks, we demonstrate that existing defense approaches are not as effective as previously reported. Next, we introduce a new approach for fine-grained privacy analysis by formulating and deriving a new metric called the privacy risk score. Our privacy risk score metric measures an individual sample's likelihood of being a training member, which allows an adversary to perform membership inference attacks with high confidence. We experimentally validate the effectiveness of the privacy risk score metric and demonstrate that the distribution of the privacy risk score across individual samples is heterogeneous. Finally, we perform an in-depth investigation for understanding why certain samples have high privacy risk scores, including correlations with model sensitivity, generalization error, and feature embeddings. Our work emphasizes the importance of a systematic and rigorous evaluation of privacy risks of machine learning models.