 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Fix for Convolutional Neural Network via Coordinate Embedding
Paper and Code


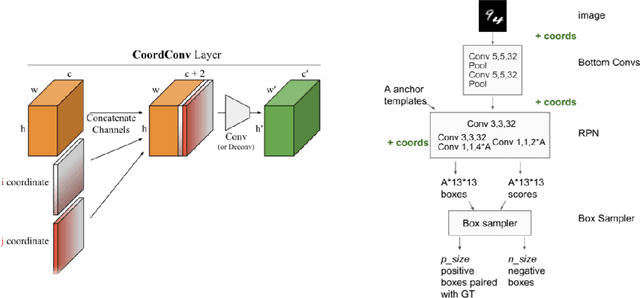
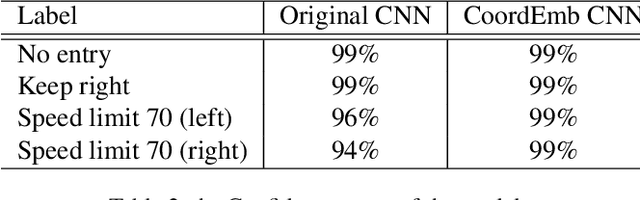
Convolutional Neural Networks (CNN) has been widely applied in the realm of computer vision. However, given the fact that CNN models are translation invariant, they are not aware of the coordinate information of each pixel. Thus the generalization ability of CNN will be limited since the coordinate information is crucial for a model to learn affine transformations which directly operate on the coordinate of each pixel. In this project, we proposed a simple approach to incorporate the coordinate information to the CNN model through coordinate embedding. Our approach does not change the downstream model architecture and can be easily applied to the pre-trained models for the task like object detection. Our experiments on the German Traffic Sign Detection Benchmark show that our approach not only significantly improve the model performance but also have better robustness with respect to the affine transformation.