 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaption Generation of Robot Behaviors based on Unsupervised Learning of Action Segments
Paper and Code
Mar 23, 2020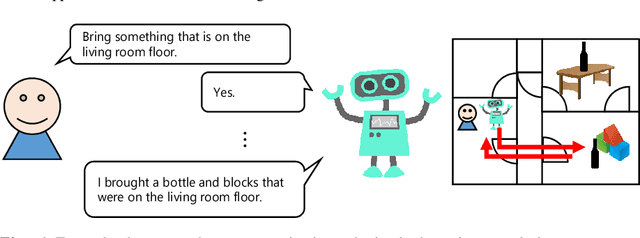

Bridging robot action sequences and their natural language captions is an important task to increase explainability of human assisting robots in their recently evolving field. In this paper, we propose a system for generating natural language captions that describe behaviors of human assisting robots. The system describes robot actions by using robot observations; histories from actuator systems and cameras, toward end-to-end bridging between robot actions and natural language captions. Two reasons make it challenging to apply existing sequence-to-sequence models to this mapping: 1) it is hard to prepare a large-scale dataset for any kind of robots and their environment, and 2) there is a gap between the number of samples obtained from robot action observations and generated word sequences of captions. We introduced unsupervised segmentation based on K-means clustering to unify typical robot observation patterns into a class. This method makes it possible for the network to learn the relationship from a small amount of data. Moreover, we utilized a chunking method based on byte-pair encoding (BPE) to fill in the gap between the number of samples of robot action observations and words in a caption. We also applied an attention mechanism to the segmentation task. Experimental results show that the proposed model based on unsupervised learning can generate better descriptions than other methods. We also show that the attention mechanism did not work well in our low-resource setting.