 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Language Relatedness to improve Machine Translation: A Case Study on Languages of the Indian Subcontinent
Paper and Code

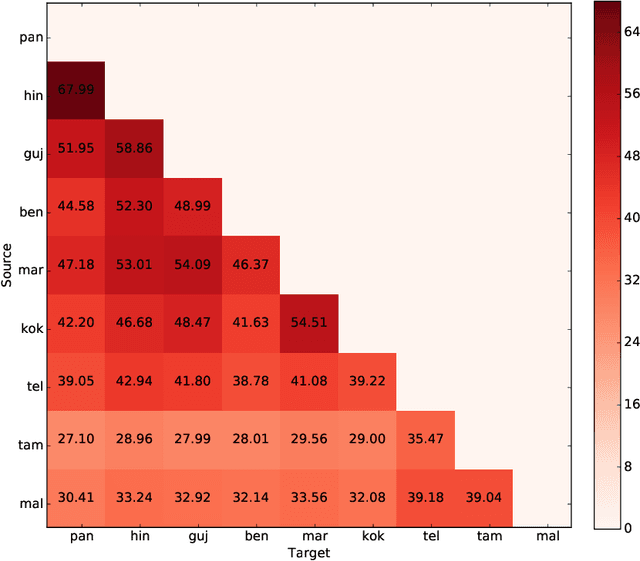
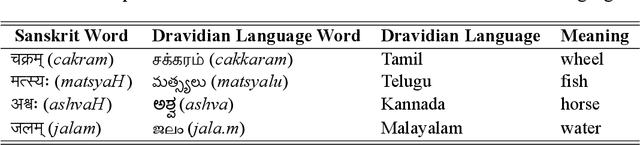
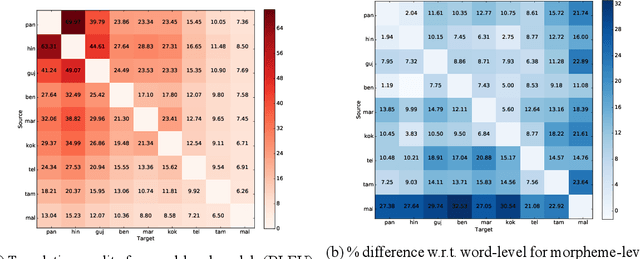
In this work, we present an extensive study of statistical machine translation involving languages of the Indian subcontinent. These languages are related by genetic and contact relationships. We describe the similarities between Indic languages arising from these relationships. We explore how lexical and orthographic similarity among these languages can be utilized to improve translation quality between Indic languages when limited parallel corpora is available. We also explore how the structural correspondence between Indic languages can be utilized to re-use linguistic resources for English to Indic language translation. Our observations span 90 language pairs from 9 Indic languages and English. To the best of our knowledge, this is the first large-scale study specifically devoted to utilizing language relatedness to improve translation between related languages.