 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarMixup: Exploiting the Latent Space for Robust Training and Inference
Paper and Code
Mar 14, 2020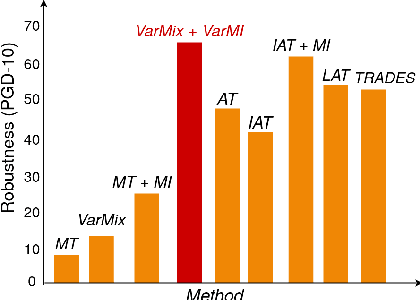

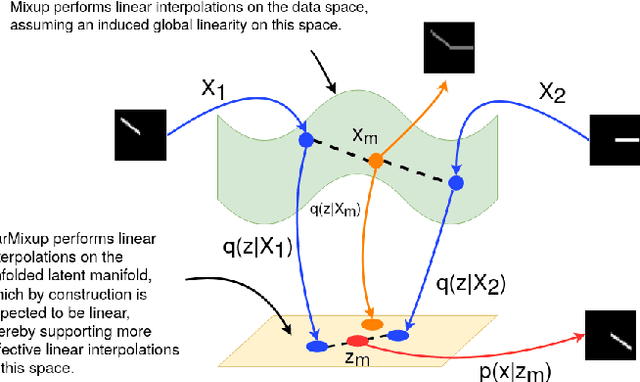
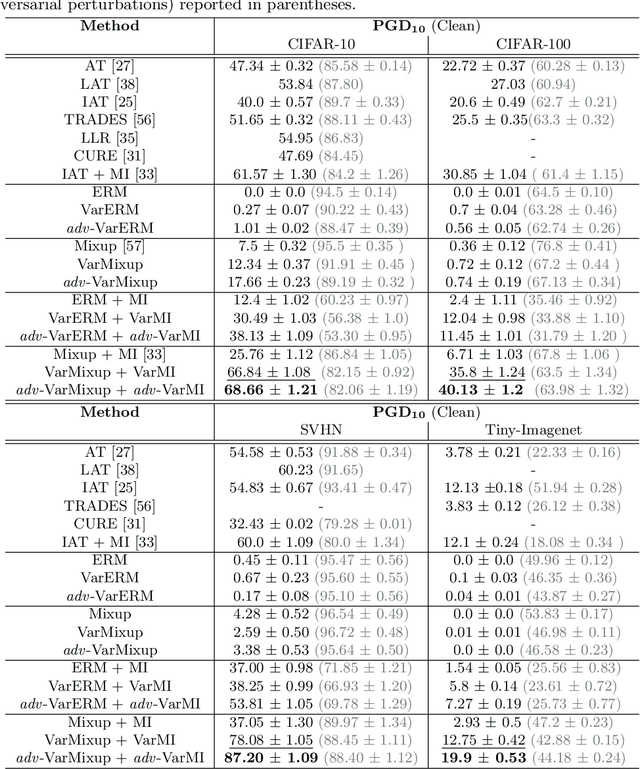
The vulnerability of Deep Neural Networks (DNNs) to adversarial attacks has led to the development of many defense approaches. Among them, Adversarial Training (AT) is a popular and widely used approach for training adversarially robust models. Mixup Training (MT), a recent popular training algorithm, improves the generalization performance of models by introducing globally linear behavior in between training examples. Although still in its early phase, we observe a shift in trend of exploiting Mixup from perspectives of generalisation to that of adversarial robustness. It has been shown that the Mixup trained models improves the robustness of models but only passively. A recent approach, Mixup Inference (MI), proposes an inference principle for Mixup trained models to counter adversarial examples at inference time by mixing the input with other random clean samples. In this work, we propose a new approach - \textit{VarMixup (Variational Mixup)} - to better sample mixup images by using the latent manifold underlying the data. Our experiments on CIFAR-10, CIFAR-100, SVHN and Tiny-Imagenet demonstrate that \textit{VarMixup} beats state-of-the-art AT techniques without training the model adversarially. Additionally, we also conduct ablations that show that models trained on \textit{VarMixup} samples are also robust to various input corruptions/perturbations, have low calibration error and are transferable.