 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Interpretability of Dual-Encoder Models for Dialogue Response Suggestions
Paper and Code
Mar 02, 2020
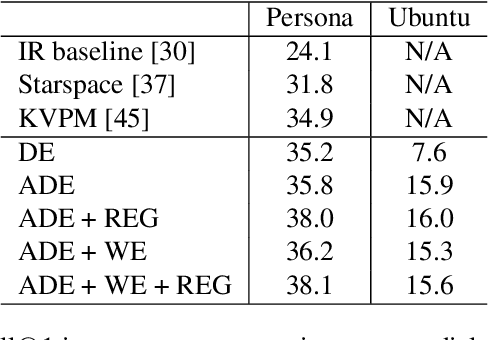
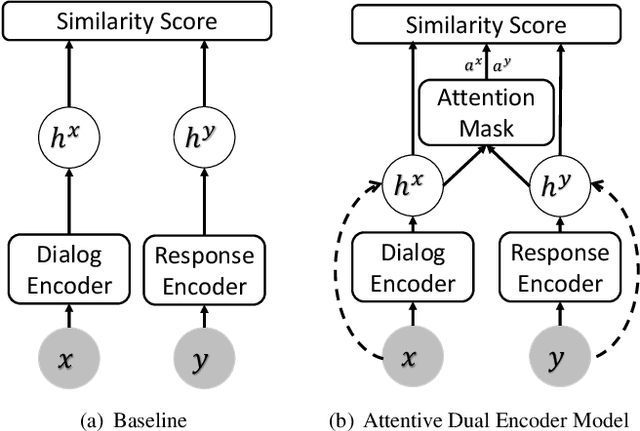
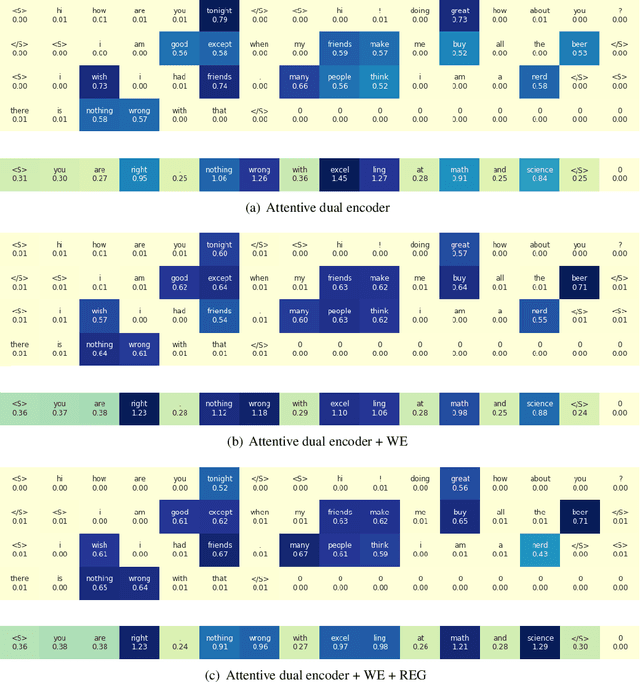
This work shows how to improve and interpret the commonly used dual encoder model for response suggestion in dialogue. We present an attentive dual encoder model that includes an attention mechanism on top of the extracted word-level features from two encoders, one for context and one for label respectively. To improve the interpretability in the dual encoder models, we design a novel regularization loss to minimize the mutual information between unimportant words and desired labels, in addition to the original attention method, so that important words are emphasized while unimportant words are de-emphasized. This can help not only with model interpretability, but can also further improve model accuracy. We propose an approximation method that uses a neural network to calculate the mutual information. Furthermore, by adding a residual layer between raw word embeddings and the final encoded context feature, word-level interpretability is preserved at the final prediction of the model. We compare the proposed model with existing methods for the dialogue response task on two public datasets (Persona and Ubuntu). The experiments demonstrate the effectiveness of the proposed model in terms of better Recall@1 accuracy and visualized interpretability.