 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReZero is All You Need: Fast Convergence at Large Depth
Paper and Code

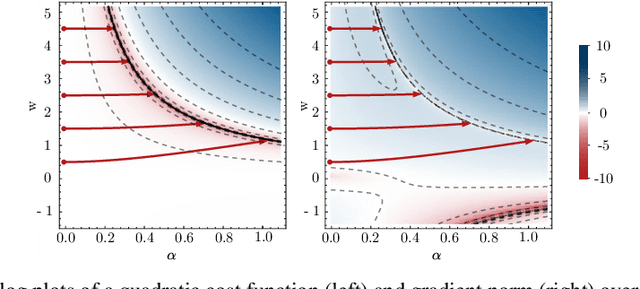

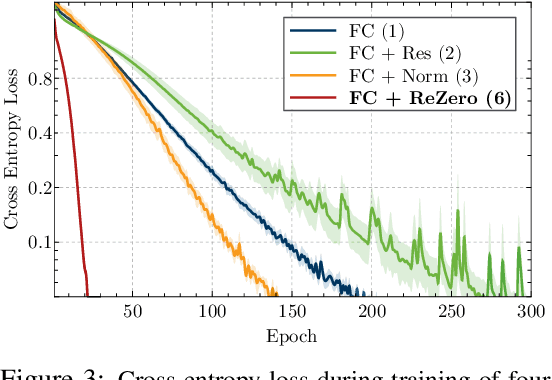
Deep networks have enabled significant performance gains across domains, but they often suffer from vanishing/exploding gradients. This is especially true for Transformer architectures where depth beyond 12 layers is difficult to train without large datasets and computational budgets. In general, we find that inefficient signal propagation impedes learning in deep networks. In Transformers, multi-head self-attention is the main cause of this poor signal propagation. To facilitate deep signal propagation, we propose ReZero, a simple change to the architecture that initializes an arbitrary layer as the identity map, using a single additional learned parameter per layer. We apply this technique to language modeling and find that we can easily train ReZero-Transformer networks over a hundred layers. When applied to 12 layer Transformers, ReZero converges 56% faster on enwiki8. ReZero applies beyond Transformers to other residual networks, enabling 1,500% faster convergence for deep fully connected networks and 32% faster convergence for a ResNet-56 trained on CIFAR 10.