 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Convolutional Neural Networks: A Deep Architecture with Innate Robustness to Partial Occlusion
Paper and Code

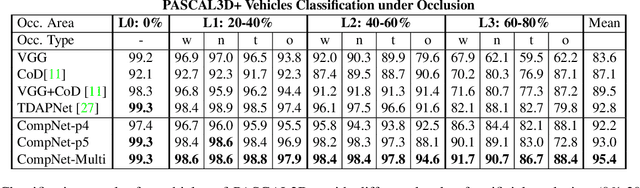
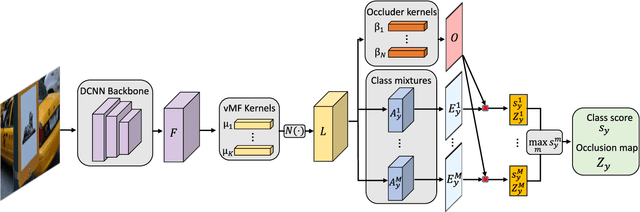
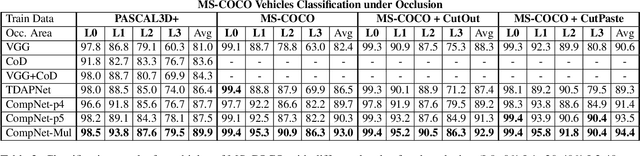
Recent findings show that deep convolutional neural networks (DCNNs) do not generalize well under partial occlusion. Inspired by the success of compositional models at classifying partially occluded objects, we propose to integrate compositional models and DCNNs into a unified deep model with innate robustness to partial occlusion. We term this architecture Compositional Convolutional Neural Network. In particular, we propose to replace the fully connected classification head of a DCNN with a differentiable compositional model. The generative nature of the compositional model enables it to localize occluders and subsequently focus on the non-occluded parts of the object. We conduct classification experiments on artificially occluded images as well as real images of partially occluded objects from the MS-COCO dataset. The results show that DCNNs do not classify occluded objects robustly, even when trained with data that is strongly augmented with partial occlusions. Our proposed model outperforms standard DCNNs by a large margin at classifying partially occluded objects, even when it has not been exposed to occluded objects during training. Additional experiments demonstrate that CompositionalNets can also localize the occluders accurately, despite being trained with class labels only. The code used in this work is publicly available.