 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Probabilistic Verification of Machine Unlearning
Paper and Code
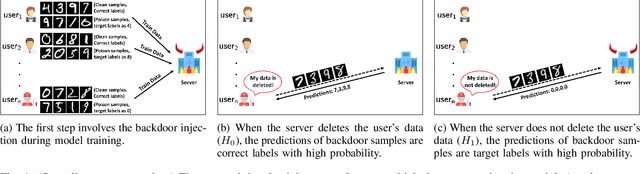
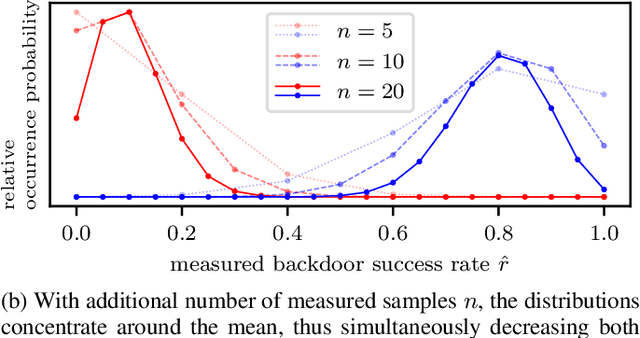
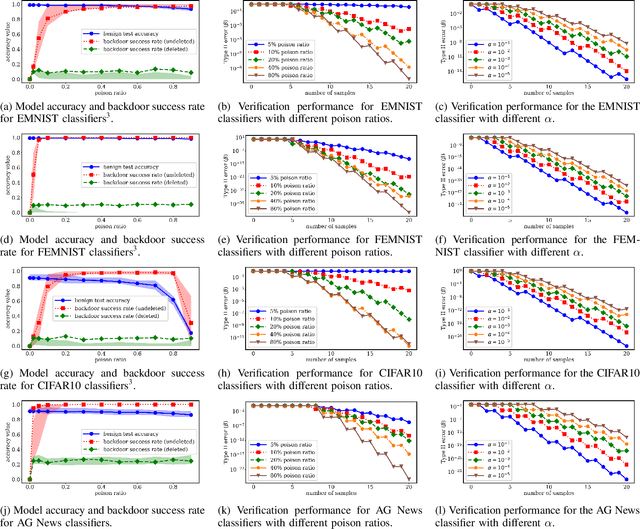
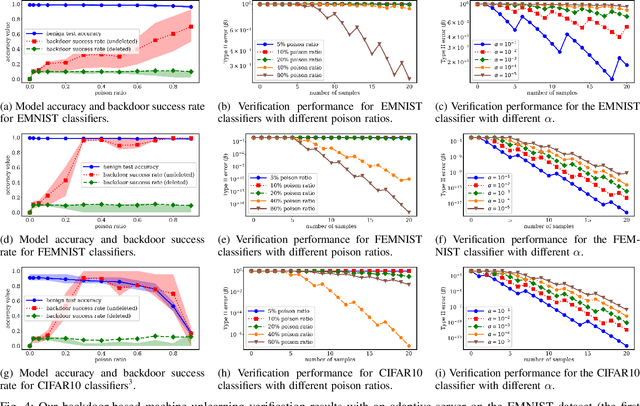
Right to be forgotten, also known as the right to erasure, is the right of individuals to have their data erased from an entity storing it. The General Data Protection Regulation in the European Union legally solidified the status of this long held notion. As a consequence, there is a growing need for the development of mechanisms whereby users can verify if service providers comply with their deletion requests. In this work, we take the first step in proposing a formal framework to study the design of such verification mechanisms for data deletion requests -- also known as machine unlearning -- in the context of systems that provide machine learning as a service. We propose a backdoor-based verification mechanism and demonstrate its effectiveness in certifying data deletion with high confidence using the above framework. Our mechanism makes a novel use of backdoor attacks in ML as a basis for quantitatively inferring machine unlearning. In our mechanism, each user poisons part of its training data by injecting a user-specific backdoor trigger associated with a user-specific target label. The prediction of target labels on test samples with the backdoor trigger is then used as an indication of the user's data being used to train the ML model. We formalize the verification process as a hypothesis testing problem, and provide theoretical guarantees on the statistical power of the hypothesis test. We experimentally demonstrate that our approach has minimal effect on the machine learning service but provides high confidence verification of unlearning. We show that with a $30\%$ poison ratio and merely $20$ test queries, our verification mechanism has both false positive and false negative ratios below $10^{-5}$. Furthermore, we also show the effectiveness of our approach by testing it against an adaptive adversary that uses a state-of-the-art backdoor defense method.