Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation using Pre-trained Transformer Models
Paper and Code
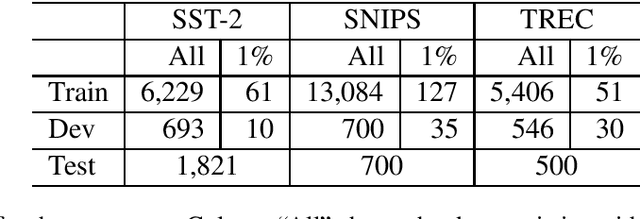

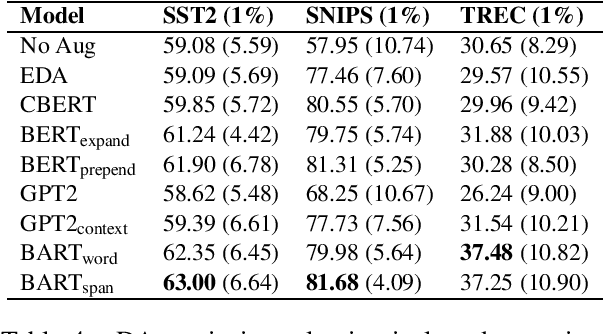
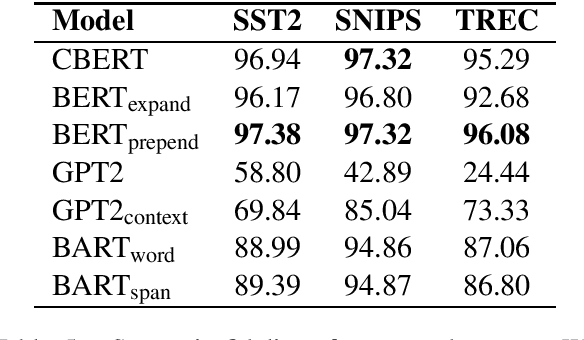
Language model based pre-trained models such as BERT have provided significant gains across different NLP tasks. In this paper, we study different types of pre-trained transformer based models such as auto-regressive models (GPT-2), auto-encoder models (BERT), and seq2seq models (BART) for conditional data augmentation. We show that prepending the class labels to text sequences provides a simple yet effective way to condition the pre-trained models for data augmentation. On three classification benchmarks, pre-trained Seq2Seq model outperforms other models. Further, we explore how different pre-trained model based data augmentation differs in-terms of data diversity, and how well such methods preserve the class-label information.
* 7 pages
View paper on