 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Trouble in Double Descent : Bias and Variance in the Lazy Regime
Paper and Code
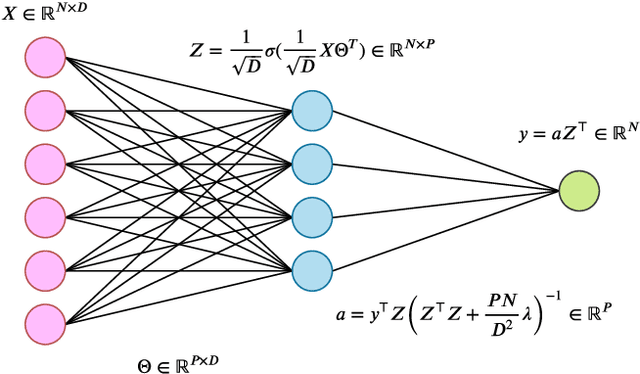
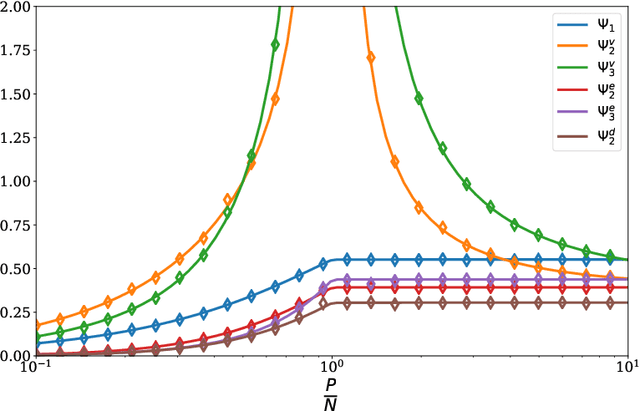
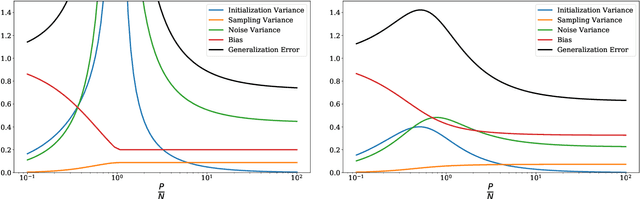
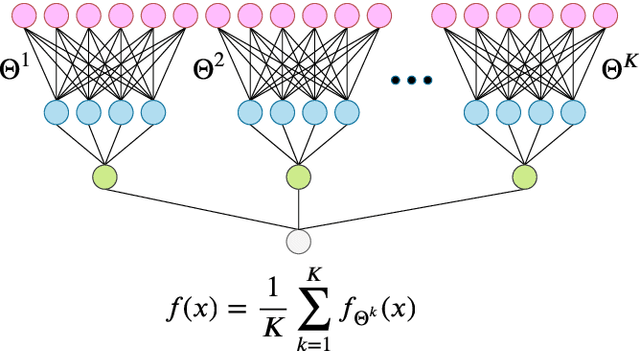
Deep neural networks can achieve remarkable generalization performances while interpolating the training data perfectly. Rather than the U-curve emblematic of the bias-variance trade-off, their test error often follows a "double descent" - a mark of the beneficial role of overparametrization. In this work, we develop a quantitative theory for this phenomenon in the so-called lazy learning regime of neural networks, by considering the problem of learning a high-dimensional function with random features regression. We obtain a precise asymptotic expression for the bias-variance decomposition of the test error, and show that the bias displays a phase transition at the interpolation threshold, beyond which it remains constant. We disentangle the variances stemming from the sampling of the dataset, from the additive noise corrupting the labels, and from the initialization of the weights. Following up on Geiger et al. 2019, we first show that the latter two contributions are the crux of the double descent: they lead to the overfitting peak at the interpolation threshold and to the decay of the test error upon overparametrization. We then quantify how they are suppressed by ensemble averaging the outputs of K independently initialized estimators. When K is sent to infinity, the test error remains constant beyond the interpolation threshold. We further compare the effects of overparametrizing, ensembling and regularizing. Finally, we present numerical experiments on classic deep learning setups to show that our results hold qualitatively in realistic lazy learning scenarios.