 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXclusion: Fairness gaps in deep chest X-ray classifiers
Paper and Code
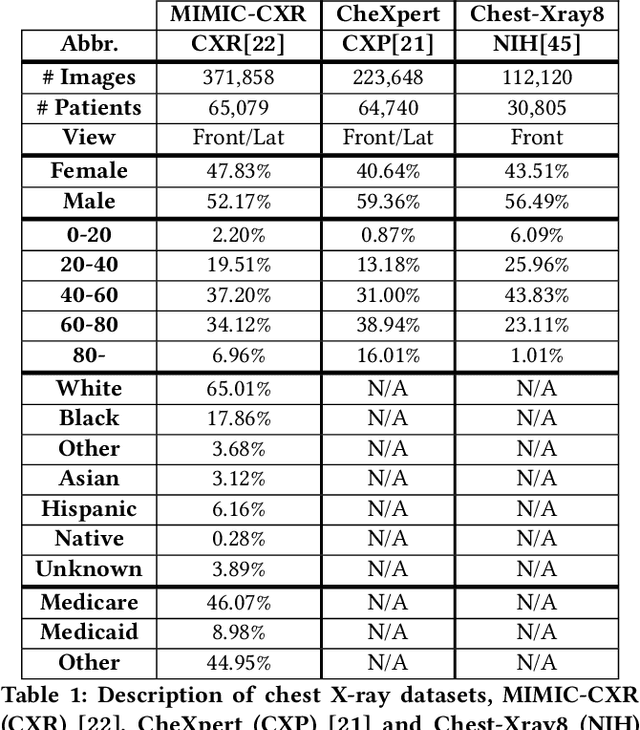
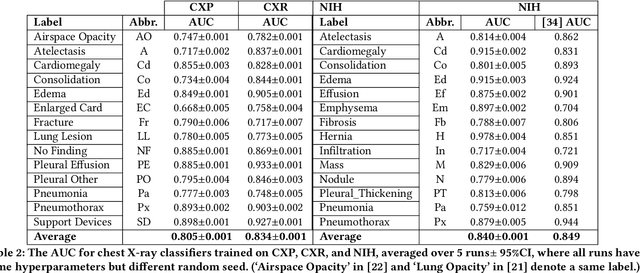
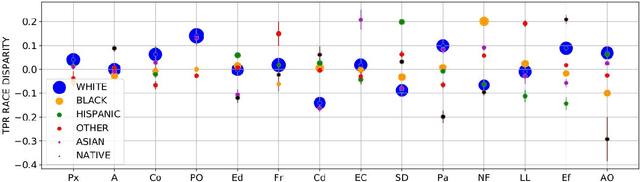
Machine learning systems have received much attention recently for their ability to achieve expert-level performance on clinical tasks, particularly in medical imaging. Here, we examine the extent to which state-of-the-art deep learning classifiers trained to yield diagnostic labels from X-ray images are biased with respect to protected attributes. We train convolution neural networks to predict 14 diagnostic labels in three prominent public chest X-ray datasets: MIMIC-CXR, Chest-Xray8, and CheXpert. We then evaluate the TPR disparity - the difference in true positive rates (TPR) and - underdiagnosis rate - the false positive rate of a non-diagnosis - among different protected attributes such as patient sex, age, race, and insurance type. We demonstrate that TPR disparities exist in the state-of-the-art classifiers in all datasets, for all clinical tasks, and all subgroups. We find that TPR disparities are most commonly not significantly correlated with a subgroup's proportional disease burden; further, we find that some subgroups and subsection of the population are chronically underdiagnosed. Such performance disparities have real consequences as models move from papers to products, and should be carefully audited prior to deployment.