 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Recovering Adversarial Examples: An Input Sensitivity Guided Method
Paper and Code
Feb 28, 2020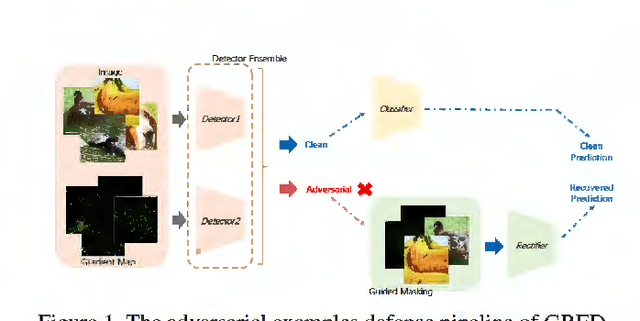
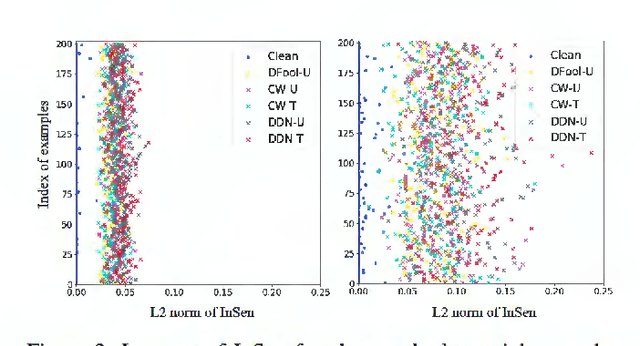
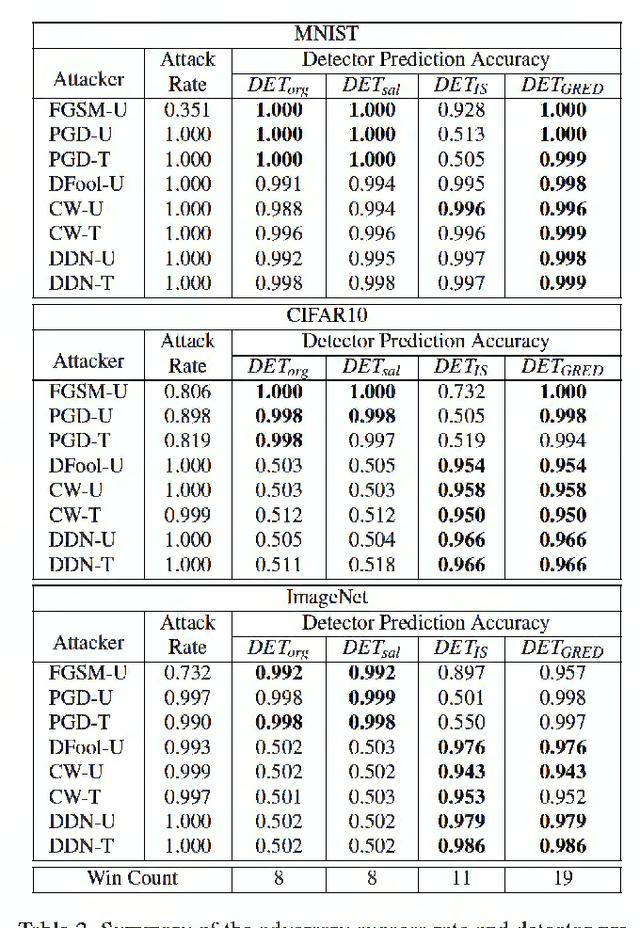
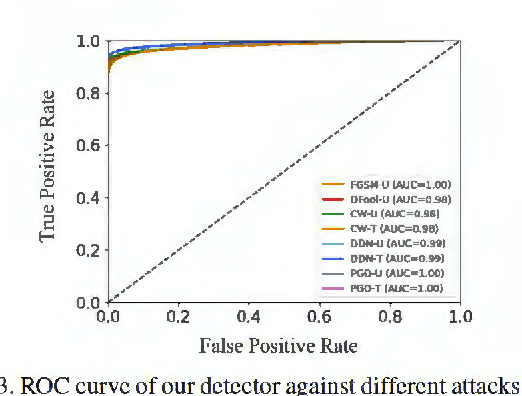
Deep neural networks undergo rapid development and achieve notable success in various tasks, including many security concerned scenarios. However, a considerable amount of works have proved its vulnerability in adversaries. To address this problem, we propose a Guided Robust and Efficient Defensive Model GRED integrating detection and recovery processes together. From the lens of the properties of gradient distribution of adversarial examples, our model detects malicious inputs effectively, as well as recovering the ground-truth label with high accuracy. Compared with commonly used adversarial training methods, our model is more efficient and outperforms state-of-the-art adversarial trained models by a large margin up to 99% on MNIST, 89 % on CIFAR-10 and 87% on ImageNet subsets. When exclusively compared with previous adversarial detection methods, the detector of GRED is robust under all threat settings with a detection rate of over 95% against most of the attacks. It is also demonstrated by empirical assessment that our model could increase attacking cost significantly resulting in either unacceptable time consuming or human perceptible image distortions.