 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Evaluation Networks
Paper and Code
Feb 26, 2020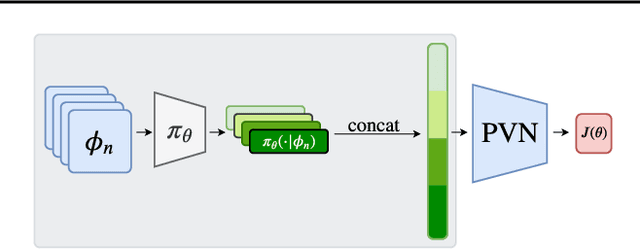
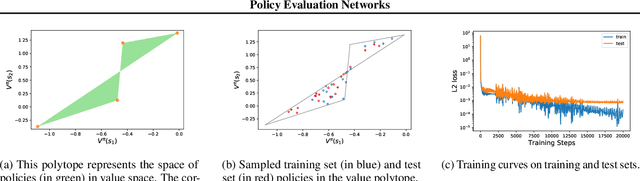
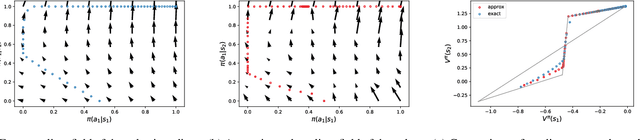
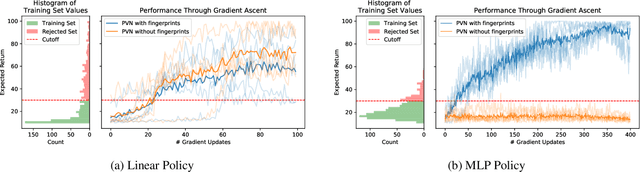
Many reinforcement learning algorithms use value functions to guide the search for better policies. These methods estimate the value of a single policy while generalizing across many states. The core idea of this paper is to flip this convention and estimate the value of many policies, for a single set of states. This approach opens up the possibility of performing direct gradient ascent in policy space without seeing any new data. The main challenge for this approach is finding a way to represent complex policies that facilitates learning and generalization. To address this problem, we introduce a scalable, differentiable fingerprinting mechanism that retains essential policy information in a concise embedding. Our empirical results demonstrate that combining these three elements (learned Policy Evaluation Network, policy fingerprints, gradient ascent) can produce policies that outperform those that generated the training data, in zero-shot manner.