 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzleNet: Scene Text Detection by Segment Context Graph Learning
Paper and Code
Feb 26, 2020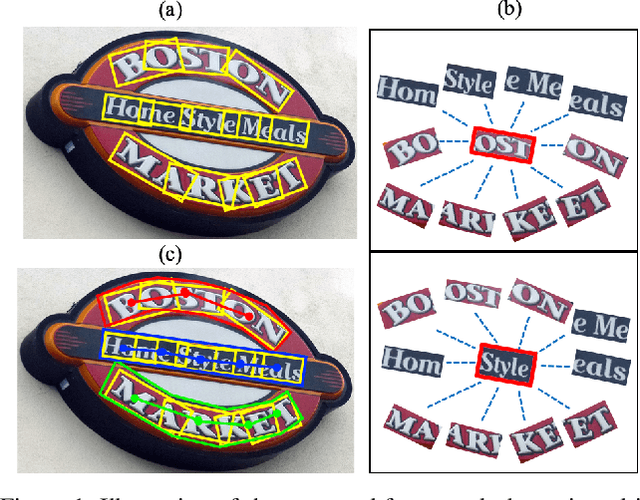
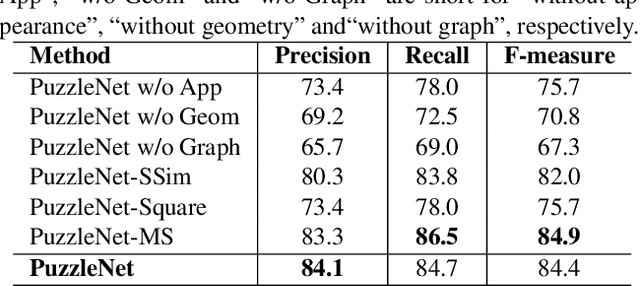
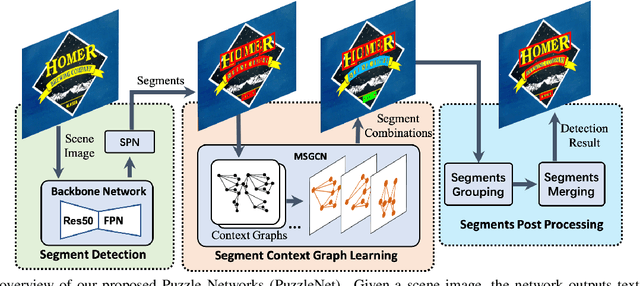
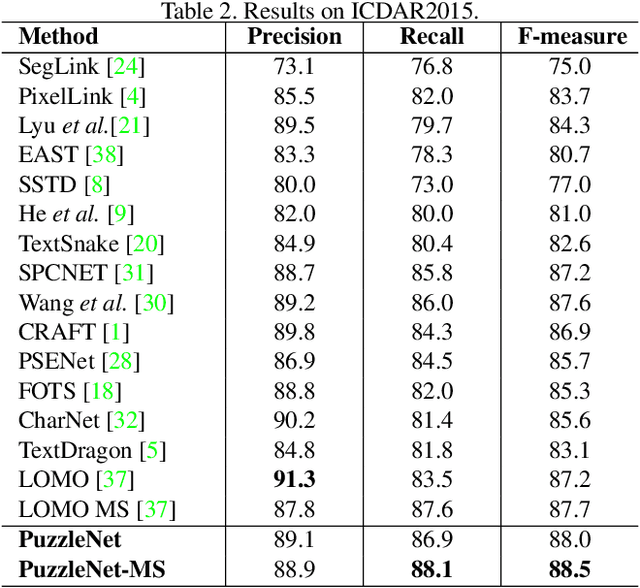
Recently, a series of decomposition-based scene text detection methods has achieved impressive progress by decomposing challenging text regions into pieces and linking them in a bottom-up manner. However, most of them merely focus on linking independent text pieces while the context information is underestimated. In the puzzle game, the solver often put pieces together in a logical way according to the contextual information of each piece, in order to arrive at the correct solution. Inspired by it, we propose a novel decomposition-based method, termed Puzzle Networks (PuzzleNet), to address the challenging scene text detection task in this work. PuzzleNet consists of the Segment Proposal Network (SPN) that predicts the candidate text segments fitting arbitrary shape of text region, and the two-branch Multiple-Similarity Graph Convolutional Network (MSGCN) that models both appearance and geometry correlations between each segment to its contextual ones. By building segments as context graphs, MSGCN effectively employs segment context to predict combinations of segments. Final detections of polygon shape are produced by merging segments according to the predicted combinations. Evaluations on three benchmark datasets, ICDAR15, MSRA-TD500 and SCUT-CTW1500, have demonstrated that our method can achieve better or comparable performance than current state-of-the-arts, which is beneficial from the exploitation of segment context graph.