 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Decentralized Learning with Sparsification and Adaptive Peer Selection
Paper and Code
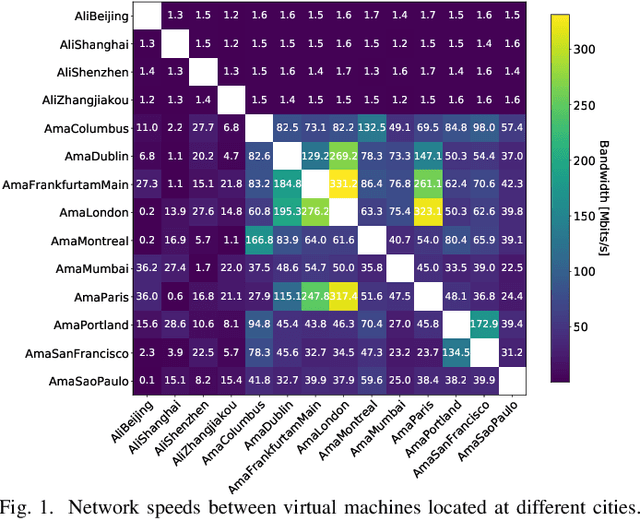
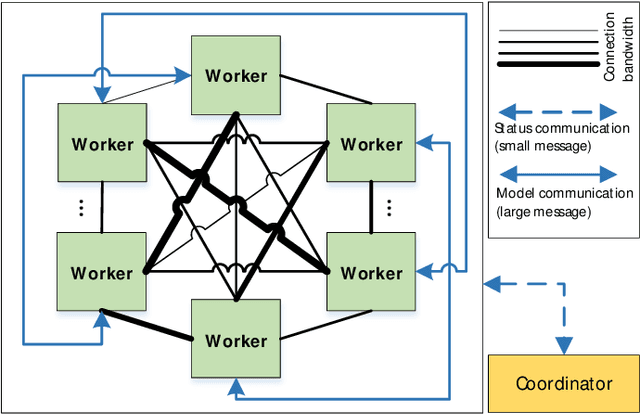
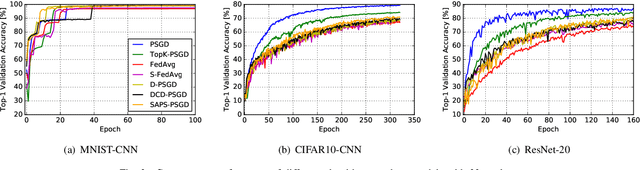
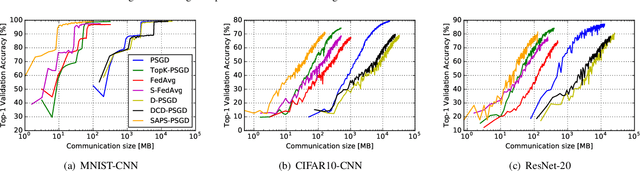
Distributed learning techniques such as federated learning have enabled multiple workers to train machine learning models together to reduce the overall training time. However, current distributed training algorithms (centralized or decentralized) suffer from the communication bottleneck on multiple low-bandwidth workers (also on the server under the centralized architecture). Although decentralized algorithms generally have lower communication complexity than the centralized counterpart, they still suffer from the communication bottleneck for workers with low network bandwidth. To deal with the communication problem while being able to preserve the convergence performance, we introduce a novel decentralized training algorithm with the following key features: 1) It does not require a parameter server to maintain the model during training, which avoids the communication pressure on any single peer. 2) Each worker only needs to communicate with a single peer at each communication round with a highly compressed model, which can significantly reduce the communication traffic on the worker. We theoretically prove that our sparsification algorithm still preserves convergence properties. 3) Each worker dynamically selects its peer at different communication rounds to better utilize the bandwidth resources. We conduct experiments with convolutional neural networks on 32 workers to verify the effectiveness of our proposed algorithm compared to seven existing methods. Experimental results show that our algorithm significantly reduces the communication traffic and generally select relatively high bandwidth peers.