 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Social Biases in Grounded Vision and Language Embeddings
Paper and Code
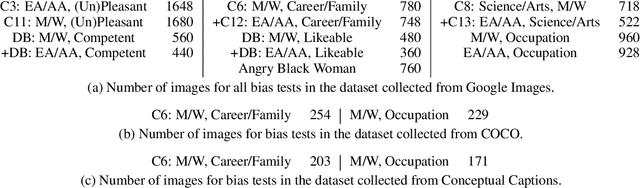


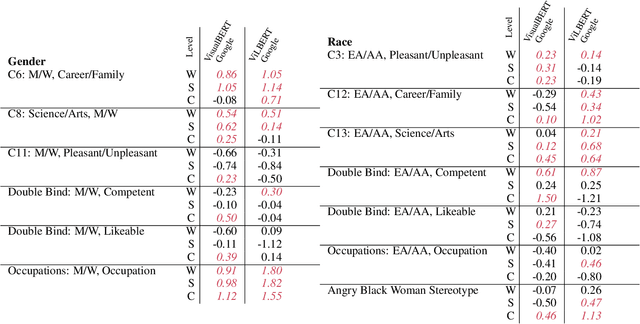
We generalize the notion of social biases from language embeddings to grounded vision and language embeddings. Biases are present in grounded embeddings, and indeed seem to be equally or more significant than for ungrounded embeddings. This is despite the fact that vision and language can suffer from different biases, which one might hope could attenuate the biases in both. Multiple ways exist to generalize metrics measuring bias in word embeddings to this new setting. We introduce the space of generalizations (Grounded-WEAT and Grounded-SEAT) and demonstrate that three generalizations answer different yet important questions about how biases, language, and vision interact. These metrics are used on a new dataset, the first for grounded bias, created by augmenting extending standard linguistic bias benchmarks with 10,228 images from COCO, Conceptual Captions, and Google Images. Dataset construction is challenging because vision datasets are themselves very biased. The presence of these biases in systems will begin to have real-world consequences as they are deployed, making carefully measuring bias and then mitigating it critical to building a fair society.