 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchoenberg-Rao distances: Entropy-based and geometry-aware statistical Hilbert distances
Paper and Code
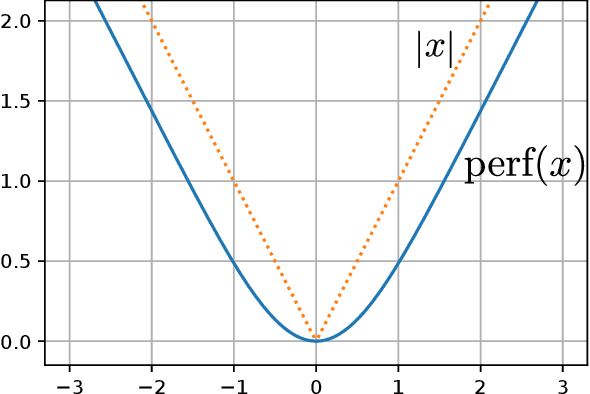
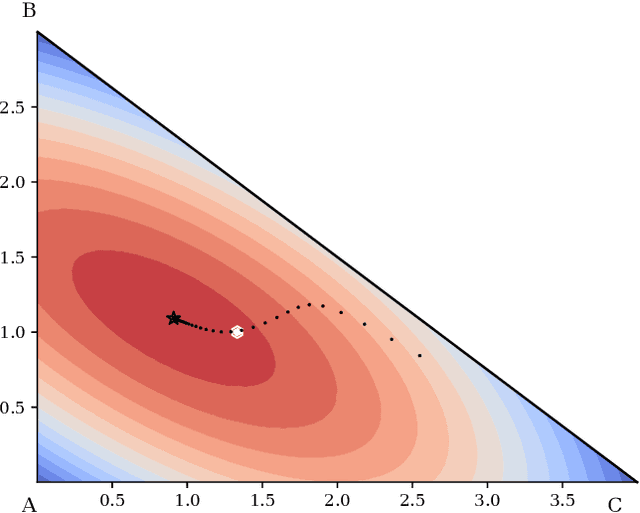
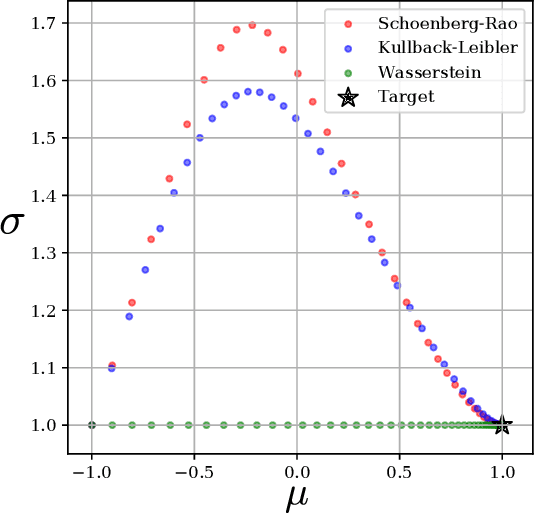
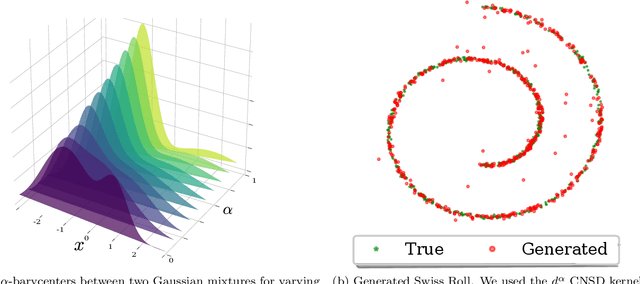
Distances between probability distributions that take into account the geometry of their sample space,like the Wasserstein or the Maximum Mean Discrepancy (MMD) distances have received a lot of attention in machine learning as they can, for instance, be used to compare probability distributions with disjoint supports. In this paper, we study a class of statistical Hilbert distances that we term the Schoenberg-Rao distances, a generalization of the MMD that allows one to consider a broader class of kernels, namely the conditionally negative semi-definite kernels. In particular, we introduce a principled way to construct such kernels and derive novel closed-form distances between mixtures of Gaussian distributions, among others. These distances, derived from the concave Rao's quadratic entropy, enjoy nice theoretical properties and possess interpretable hyperparameters which can be tuned for specific applications. Our method constitutes a practical alternative to Wasserstein distances and we illustrate its efficiency on a broad range of machine learning tasks such as density estimation, generative modeling and mixture simplification.