 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealtime Index-Free Single Source SimRank Processing on Web-Scale Graphs
Paper and Code
Feb 19, 2020
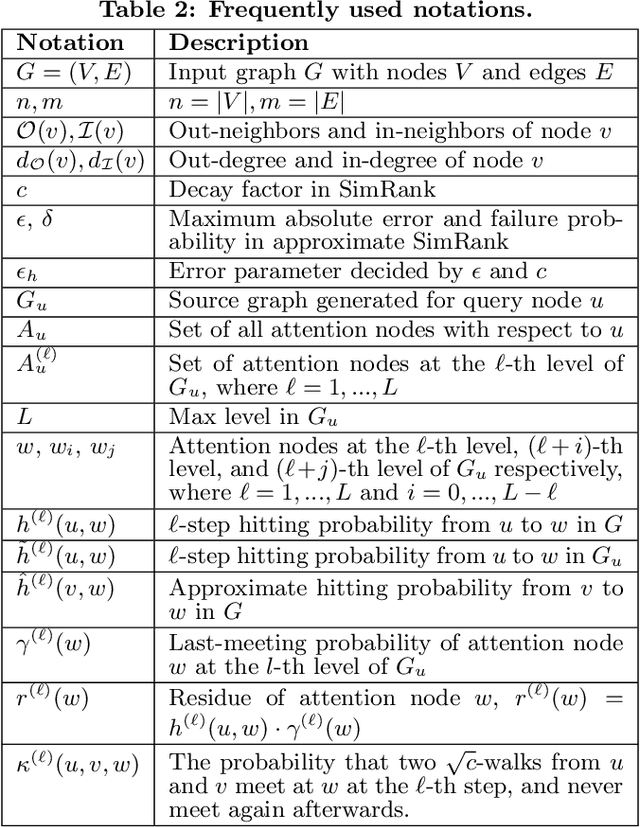
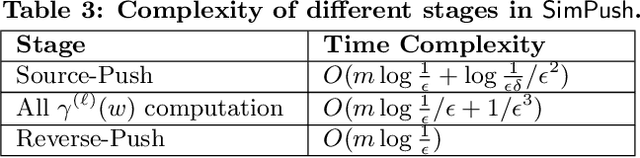

Given a graph G and a node u in G, a single source SimRank query evaluates the similarity between u and every node v in G. Existing approaches to single source SimRank computation incur either long query response time, or expensive pre-computation, which needs to be performed again whenever the graph G changes. Consequently, to our knowledge none of them is ideal for scenarios in which (i) query processing must be done in realtime, and (ii) the underlying graph G is massive, with frequent updates. Motivated by this, we propose SimPush, a novel algorithm that answers single source SimRank queries without any pre-computation, and at the same time achieves significantly higher query processing speed than even the fastest known index-based solutions. Further, SimPush provides rigorous result quality guarantees, and its high performance does not rely on any strong assumption of the underlying graph. Specifically, compared to existing methods, SimPush employs a radically different algorithmic design that focuses on (i) identifying a small number of nodes relevant to the query, and subsequently (ii) computing statistics and performing residue push from these nodes only. We prove the correctness of SimPush, analyze its time complexity, and compare its asymptotic performance with that of existing methods. Meanwhile, we evaluate the practical performance of SimPush through extensive experiments on 8 real datasets. The results demonstrate that SimPush consistently outperforms all existing solutions, often by over an order of magnitude. In particular, on a commodity machine, SimPush answers a single source SimRank query on a web graph containing over 133 million nodes and 5.4 billion edges in under 62 milliseconds, with 0.00035 empirical error, while the fastest index-based competitor needs 1.18 seconds.