 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinBERT: Distilling Knowledge to Twin-Structured BERT Models for Efficient Retrieval
Paper and Code
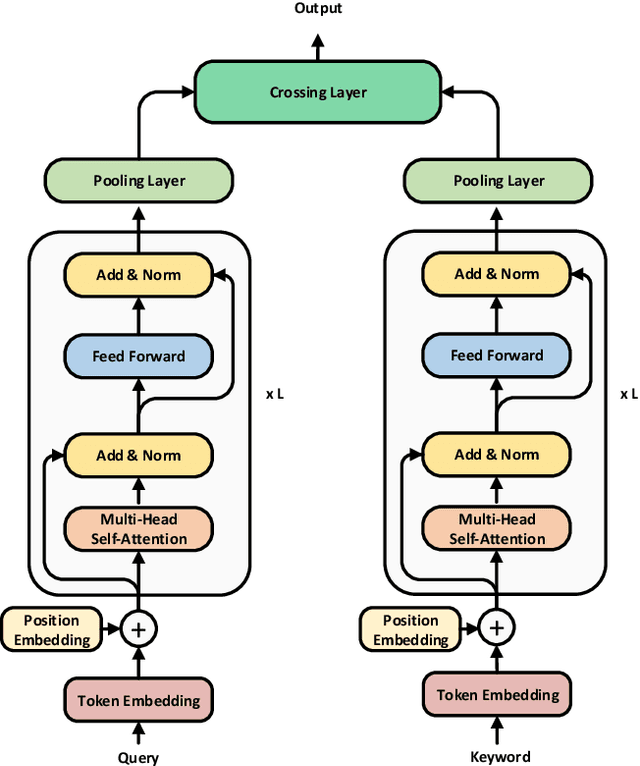
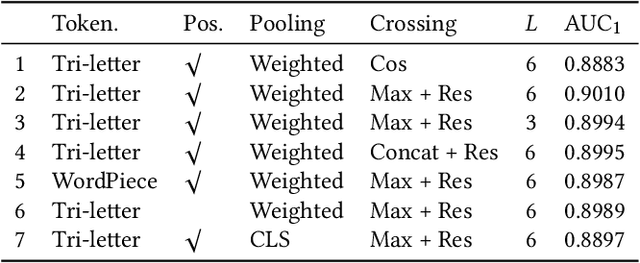
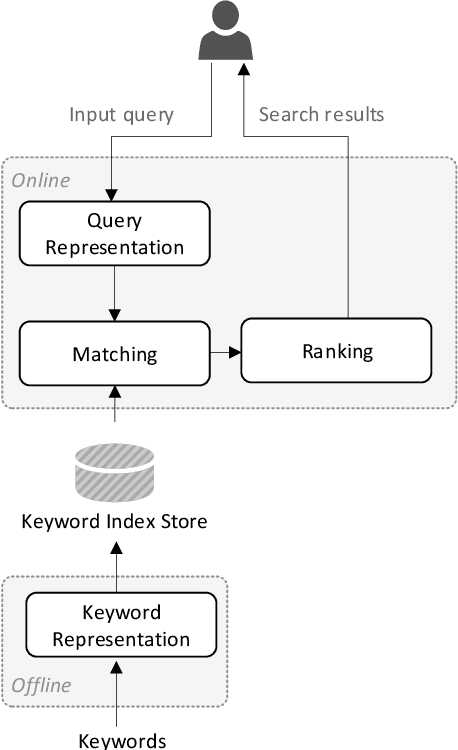
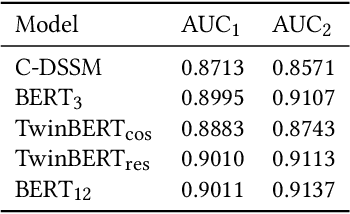
Pre-trained language models like BERT have achieved great success in a wide variety of NLP tasks, while the superior performance comes with high demand in computational resources, which hinders the application in low-latency IR systems. We present TwinBERT model for effective and efficient retrieval, which has twin-structured BERT-like encoders to represent query and document respectively and a crossing layer to combine the embeddings and produce a similarity score. Different from BERT, where the two input sentences are concatenated and encoded together, TwinBERT decouples them during encoding and produces the embeddings for query and document independently, which allows document embeddings to be pre-computed offline and cached in memory. Thereupon, the computation left for run-time is from the query encoding and query-document crossing only. This single change can save large amount of computation time and resources, and therefore significantly improve serving efficiency. Moreover, a few well-designed network layers and training strategies are proposed to further reduce computational cost while at the same time keep the performance as remarkable as BERT model. Lastly, we develop two versions of TwinBERT for retrieval and relevance tasks correspondingly, and both of them achieve close or on-par performance to BERT-Base model. The model was trained following the teacher-student framework and evaluated with data from one of the major search engines. Experimental results showed that the inference time was significantly reduced and was firstly controlled around 20ms on CPUs while at the same time the performance gain from fine-tuned BERT-Base model was mostly retained. Integration of the models into production systems also demonstrated remarkable improvements on relevance metrics with negligible influence on latency.