 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaylorized Training: Towards Better Approximation of Neural Network Training at Finite Width
Paper and Code
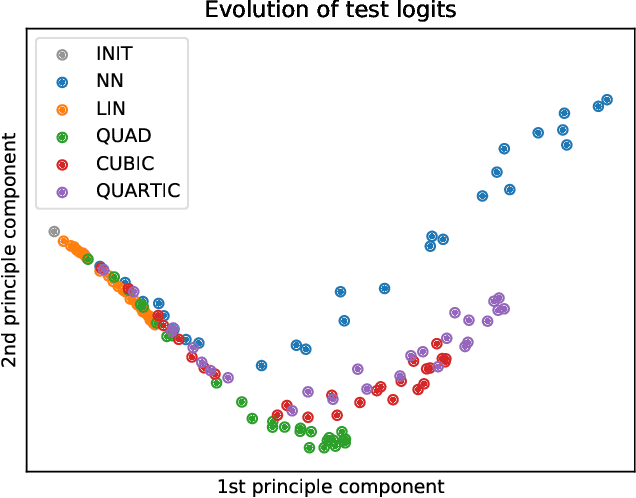

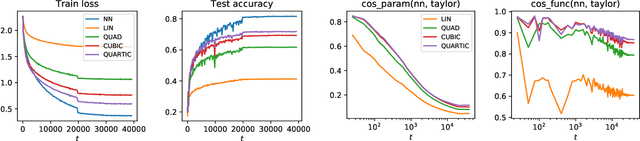
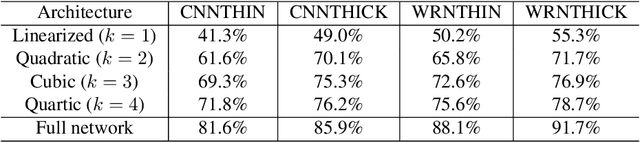
We propose \emph{Taylorized training} as an initiative towards better understanding neural network training at finite width. Taylorized training involves training the $k$-th order Taylor expansion of the neural network at initialization, and is a principled extension of linearized training---a recently proposed theory for understanding the success of deep learning. We experiment with Taylorized training on modern neural network architectures, and show that Taylorized training (1) agrees with full neural network training increasingly better as we increase $k$, and (2) can significantly close the performance gap between linearized and full training. Compared with linearized training, higher-order training works in more realistic settings such as standard parameterization and large (initial) learning rate. We complement our experiments with theoretical results showing that the approximation error of $k$-th order Taylorized models decay exponentially over $k$ in wide neural networks.