 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification Algorithm of Speech Data of Parkinsons Disease Based on Convolution Sparse Kernel Transfer Learning with Optimal Kernel and Parallel Sample Feature Selection
Paper and Code
Feb 10, 2020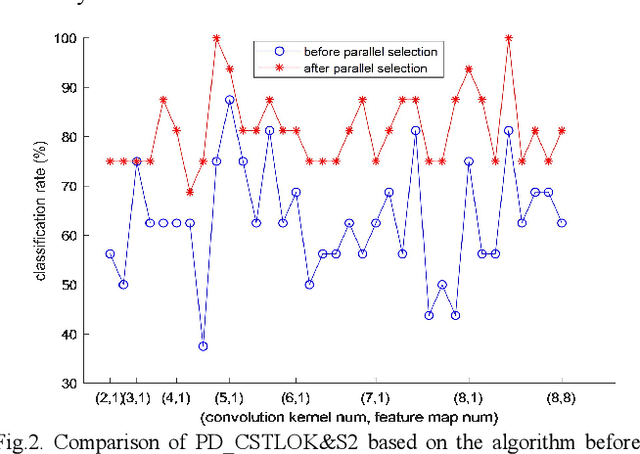
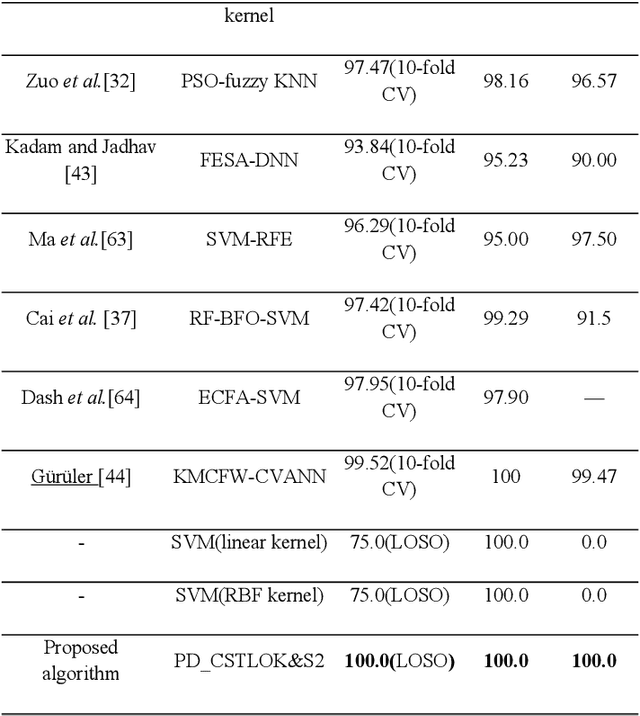
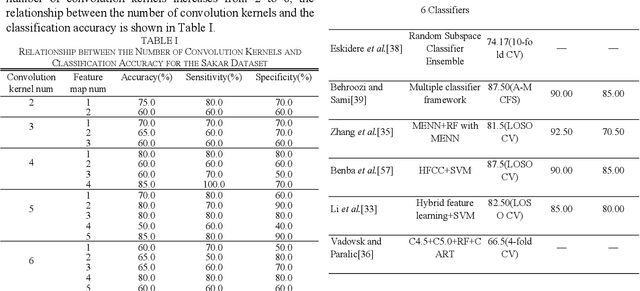

Labeled speech data from patients with Parkinsons disease (PD) are scarce, and the statistical distributions of training and test data differ significantly in the existing datasets. To solve these problems, dimensional reduction and sample augmentation must be considered. In this paper, a novel PD classification algorithm based on sparse kernel transfer learning combined with a parallel optimization of samples and features is proposed. Sparse transfer learning is used to extract effective structural information of PD speech features from public datasets as source domain data, and the fast ADDM iteration is improved to enhance the information extraction performance. To implement the parallel optimization, the potential relationships between samples and features are considered to obtain high-quality combined features. First, features are extracted from a specific public speech dataset to construct a feature dataset as the source domain. Then, the PD target domain, including the training and test datasets, is encoded by convolution sparse coding, which can extract more in-depth information. Next, parallel optimization is implemented. To further improve the classification performance, a convolution kernel optimization mechanism is designed. Using two representative public datasets and one self-constructed dataset, the experiments compare over thirty relevant algorithms. The results show that when taking the Sakar dataset, MaxLittle dataset and DNSH dataset as target domains, the proposed algorithm achieves obvious improvements in classification accuracy. The study also found large improvements in the algorithms in this paper compared with nontransfer learning approaches, demonstrating that transfer learning is both more effective and has a more acceptable time cost.