 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Melody Generation via Disentangled Short-Term Representations and Structural Conditions
Paper and Code
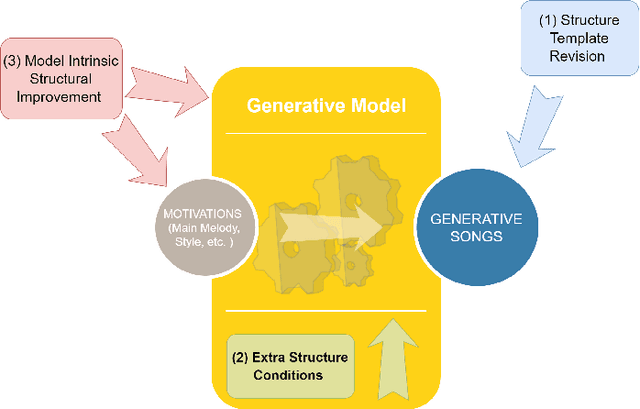

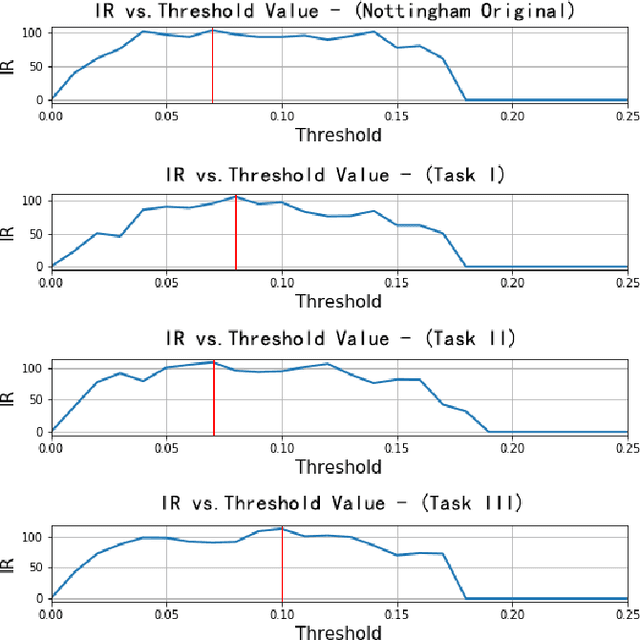
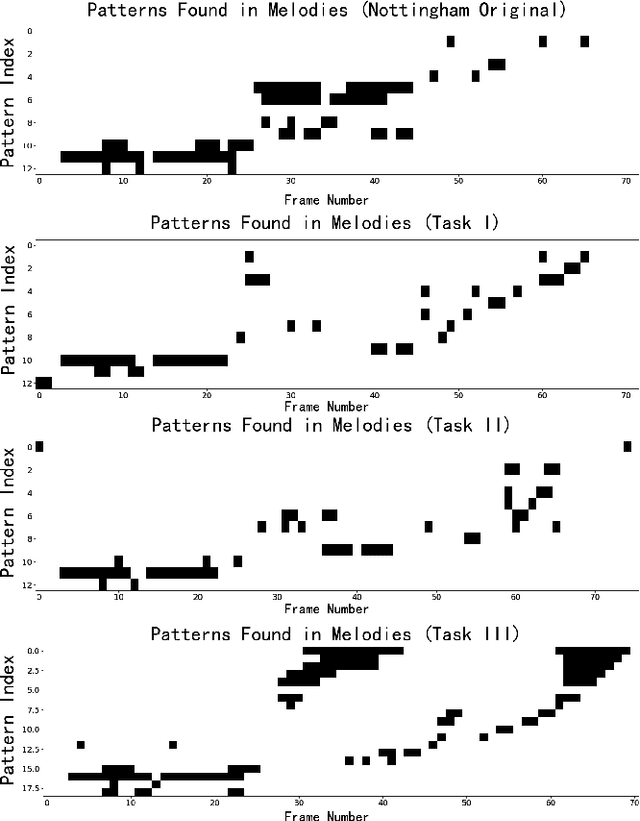
Automatic music generation is an interdisciplinary research topic that combines computational creativity and semantic analysis of music to create automatic machine improvisations. An important property of such a system is allowing the user to specify conditions and desired properties of the generated music. In this paper we designed a model for composing melodies given a user specified symbolic scenario combined with a previous music context. We add manual labeled vectors denoting external music quality in terms of chord function that provides a low dimensional representation of the harmonic tension and resolution. Our model is capable of generating long melodies by regarding 8-beat note sequences as basic units, and shares consistent rhythm pattern structure with another specific song. The model contains two stages and requires separate training where the first stage adopts a Conditional Variational Autoencoder (C-VAE) to build a bijection between note sequences and their latent representations, and the second stage adopts long short-term memory networks (LSTM) with structural conditions to continue writing future melodies. We further exploit the disentanglement technique via C-VAE to allow melody generation based on pitch contour information separately from conditioning on rhythm patterns. Finally, we evaluate the proposed model using quantitative analysis of rhythm and the subjective listening study. Results show that the music generated by our model tends to have salient repetition structures, rich motives, and stable rhythm patterns. The ability to generate longer and more structural phrases from disentangled representations combined with semantic scenario specification conditions shows a broad application of our model.