 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Batch Training Does Not Need Warmup
Paper and Code
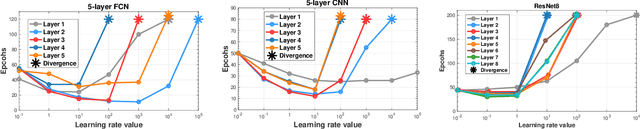
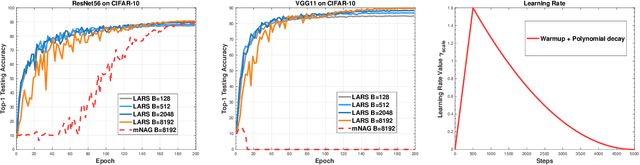
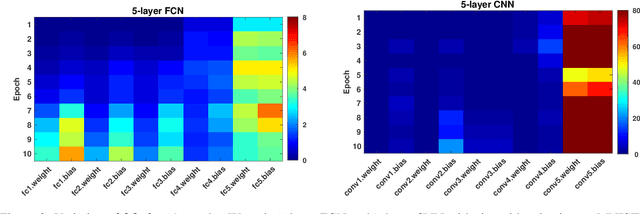
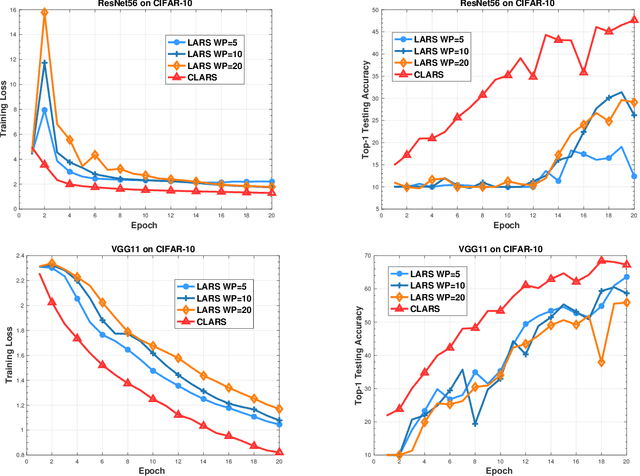
Training deep neural networks using a large batch size has shown promising results and benefits many real-world applications. However, the optimizer converges slowly at early epochs and there is a gap between large-batch deep learning optimization heuristics and theoretical underpinnings. In this paper, we propose a novel Complete Layer-wise Adaptive Rate Scaling (CLARS) algorithm for large-batch training. We also analyze the convergence rate of the proposed method by introducing a new fine-grained analysis of gradient-based methods. Based on our analysis, we bridge the gap and illustrate the theoretical insights for three popular large-batch training techniques, including linear learning rate scaling, gradual warmup, and layer-wise adaptive rate scaling. Extensive experiments demonstrate that the proposed algorithm outperforms gradual warmup technique by a large margin and defeats the convergence of the state-of-the-art large-batch optimizer in training advanced deep neural networks (ResNet, DenseNet, MobileNet) on ImageNet dataset.