 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Reasons for Outfit Evaluation with Gradient Penalty
Paper and Code
Feb 02, 2020
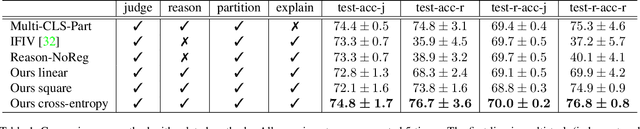
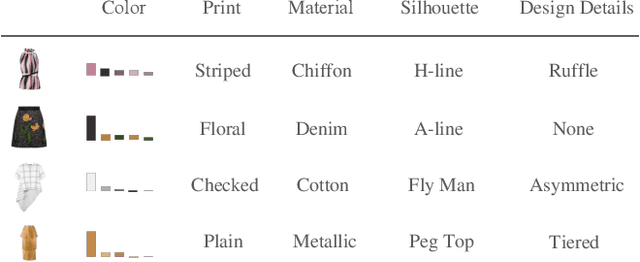
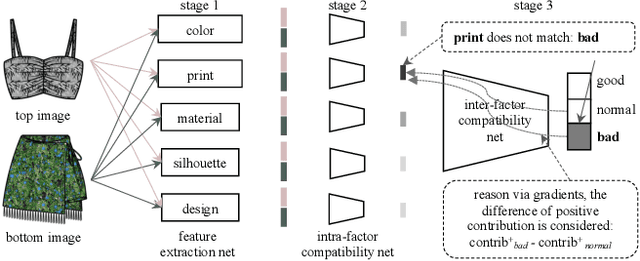
In this paper, we build an outfit evaluation system which provides feedbacks consisting of a judgment with a convincing explanation. The system is trained in a supervised manner which faithfully follows the domain knowledge in fashion. We create the EVALUATION3 dataset which is annotated with judgment, the decisive reason for the judgment, and all corresponding attributes (e.g. print, silhouette, and material \etc.). In the training process, features of all attributes in an outfit are first extracted and then concatenated as the input for the intra-factor compatibility net. Then, the inter-factor compatibility net is used to compute the loss for judgment. We penalize the gradient of judgment loss of so that our Grad-CAM-like reason is regularized to be consistent with the labeled reason. In inference, according to the obtained information of judgment, reason, and attributes, a user-friendly explanation sentence is generated by the pre-defined templates. The experimental results show that the obtained network combines the advantages of high precision and good interpretation.