 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropClass and DropAdapt: Dropping classes for deep speaker representation learning
Paper and Code
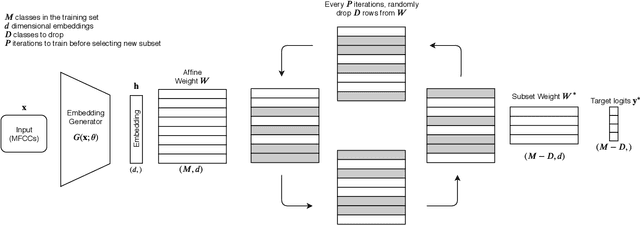
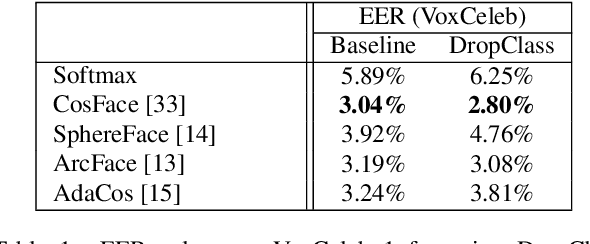
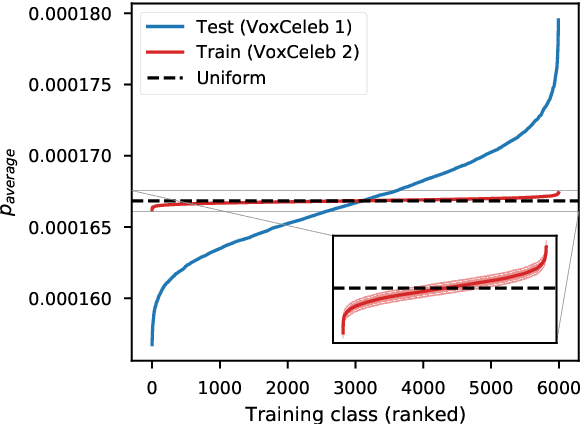
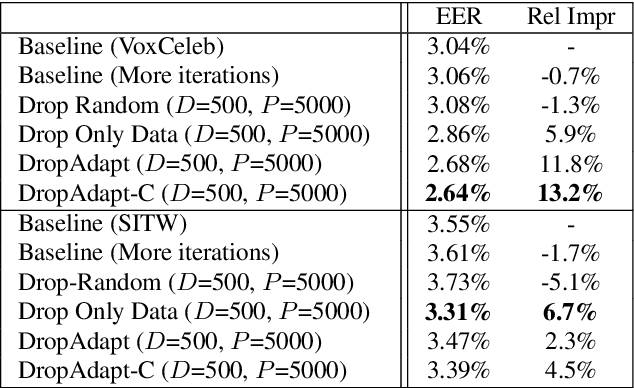
Many recent works on deep speaker embeddings train their feature extraction networks on large classification tasks, distinguishing between all speakers in a training set. Empirically, this has been shown to produce speaker-discriminative embeddings, even for unseen speakers. However, it is not clear that this is the optimal means of training embeddings that generalize well. This work proposes two approaches to learning embeddings, based on the notion of dropping classes during training. We demonstrate that both approaches can yield performance gains in speaker verification tasks. The first proposed method, DropClass, works via periodically dropping a random subset of classes from the training data and the output layer throughout training, resulting in a feature extractor trained on many different classification tasks. Combined with an additive angular margin loss, this method can yield a 7.9% relative improvement in equal error rate (EER) over a strong baseline on VoxCeleb. The second proposed method, DropAdapt, is a means of adapting a trained model to a set of enrolment speakers in an unsupervised manner. This is performed by fine-tuning a model on only those classes which produce high probability predictions when the enrolment speakers are used as input, again also dropping the relevant rows from the output layer. This method yields a large 13.2% relative improvement in EER on VoxCeleb. The code for this paper has been made publicly available.